
Hi,
I've discovered a problem I'm hoping someone can advice on an easy solution for. In short, the replication processor dosen't appear to handle record locks on ReplQueue. I'm guessing it's by design, as it should only ever be locked by the processor itself, but I've discovered a situation where it could remain locked by the front end GUI....this is occurring on a database with ~2000 tables, and every one of them is replicated to an MS SQL DB, running real time.
1. Transaction started.
2. A record is created or updated on TableA
3. The program which made this change has a "Release TableA." command.
4. Then a period of time occurs before the transactions is committed.
The 'Release' command in step 3 is instigating the triggers attached to TableA, which is creating the ReplQueue record, but leaving all records locked, including the ReplQueue record. The replication engine detects the ReplQueue entry, performs the push to SQL, then tries to delete the ReplQueue record, but can't because it's still locked by the Users session, leaving the replication engine stuck until it either crashes due to wait time expire or the transaction is committed.
There are 2 problems here, (although I'm thinking there's one solution) the first is that the replication engine is then hanging until the user clears the lock or it crashes, and the second is that if the transaction is never committed, it will actually leave replicated record in the SQL database, until either (if it was a create event) a new record is created with the same RECID, or (if it was an update event) a subsequent event occurs on that record which then refreshes the SQL version of the record.
Ideally I'd like to see the Replication engine skip records that are locked, as this would prevent both problems. Unfortunately I can't change the GUI coding to avoid pending transactions from staying open, which regardless of this problem isn't a great idea.
Any advice greatly appreciated,
Thanks,
Sam
Hi,
What version of Pro2 are you using?
Hi Sam,
Pro2 is taking care of the locking because in the logfiles of the thread you can find things like this:
06-06-2018 15:08:22 - Replication Queue Finished (ReplBlock). Processed a total of 216 records. Total time to process these items was: 00:00:01
06-06-2018 15:08:22 - 3 records were locked, and
3 transactions were open during this run.
Every run it checks whether the records are available and unlocked yet or not. If not, they are not processed and re-checked every run till they are.
But I guess we have the same issue as you. In the past 2 months it happened 3 times. The thread crashes and after a restart, it crashes immediately. I guess, it is not the replqueue-record that is locked because I'm able to change the replqueue.qthread-field of that record (I change it to 6 so no other thread will pick it up). After changing the thread of the first replqueue-record that is not yet applied, pro2 works fine.
I have no clue how this can happen, I'm still in "investigation phase"..
Pro2 version 5.0.2.
Kind regards,
Peggy
Hi Sam,
Apparently my issue is caused by what's written in this article: knowledgebase.progress.com/.../PRO2-Bulk-load-failed-due-to-data-exceeding-32000
In our sql-database there are 3 records where then content of 1 field is longer then 32000 and now and update of this sql-record is not possible because it can't be read anymore from within Progress. I did an update of the sql-record (in sql mgmt studio) and now progress can access the records and update them with what's is the replqueue-table...
Maybe it will help you too...
I am seeing the following error in the replproc20190513-2.log
Lock wait timeout of 1800 seconds expired (8812)
So the replication process is locked out and quit.
There are 5 threads ( this one is thread #2 as you see).
What could be locking out replication process? And is it REPL table lock or an application table lock?
Thanks
Actually, the Lock wait timeout error (8812) is in four threads out of five.
replproc20190513-2.log
replproc20190513-3.log
replproc20190513-4.log
replproc20190513-5.log
All those 4 threads are processing the same one table "inv-balance".
Thread #1 is processing all other tables in our application and it works fine.
pro2sql version 4.6.7
Hi Dmitri,
[quote user="Dmitri Levin"]
All those 4 threads are processing the same one table "inv-balance".
Thanks Mike. I will check it.
Valeriy,
1. What do you mean by "split replication threads"?
The table's write trigger randomly assigns records to the threads
repl.ReplQueue.QThread = RANDOM(2,5).
So each record is going to it's own randomly chosen thread.
How in that case two threads could be trying to write changes to the same target record.
2. What is a "compression trigger" ?
3. enable advanced logging for replbatch processes (Verbose).
How do I do that?
The issue we see is happening once a week, or in 2 weeks. How big the logs should be in Verbose case? The table has millions of changes per day.
pro2sql version 4.6.7
Hi Dmitri,
> 1. "split replication threads"
- unfortunately, you're using the old version. This feature appeared later. As I recall, in V. 5.0.3.
Just using RANDOM(2.5) is not enough,it's a bit more complicated. A trigger with "split replication threads" distributes notes across threads based on the source record's RECID (modulo). This is more correct because change notes for the same record will always be created in the same thread.
Download the last version, and look at the template tplt_repltrig_split_with_compression.p.
> 2. What is a "compression trigger" ?
When a record changes several times in a short period of time and the replication process does not have time to process that change notes, many of these notes accumulate in the queue for the same record.
At the same time, you distribute the changes to the record among the threads using the RANDOM function. Therefore, it is possible that change notes for the same record are created in different threads. This is possible causes a lock conflict when two different threads try to process changes for the same record at the same time. In your case, it probably doesn't happen often, but it does (is happening once a week, or in 2 weeks).
A replication trigger with compression before creating a change note, first checks for an unapplied note for the same record in the replication queue. If such a note still exists in the queue, the trigger simply updates the information in that note. This is useful for both high-activity tables (reduce the total amount of notes) and to avoid conflicts over access to the same Oracle-side record by different replication threads.
In your version Pro2 look how compression works in template tplt_repltrig_with_compression.p.
>3. enable advanced logging for replbatch processes (Verbose).
>How do I do that?
You can do it online. See the screenshot
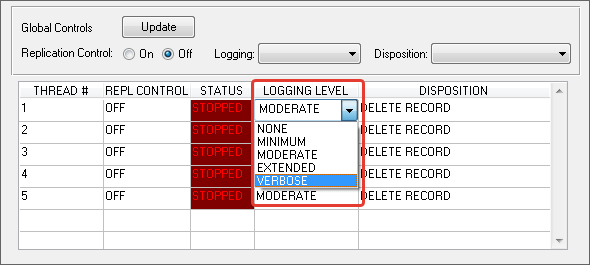
>How big the logs should be in Verbose case?
Very large. But this is acceptable during the search for errors.
We use logrotate on linux to archive these logs.
Regards,
Valeriy
Thank you very much Valeriy
1. "split replication threads"
I will change the RANDOM(2.5) to use ( integer( RECID( table-name )) mod 10) mod 4 + 2.
We are not going to upgrade to version 5, as I heard Pro2 version 6 should be released soon.
2. "compression trigger" tplt_repltrig_with_compression.p
I do not think that will work with ver 4 pro2 repl DB schema. The following code requires an index
FIND FIRST ReplQueue WHERE ReplQueue.SrcDB = "<<SOURCE_DB>>"
AND ReplQueue.SrcTable = "<<SRC_TABLE>>"
AND ReplQueue.SrcRecord = strRecID
EXCLUSIVE-LOCK NO-WAIT NO-ERROR.
And in ver 4 there is there is no index supporting that FIND.
With thousands ReplQueue records that FIND will work very slow and kill the system.
May be in ver 5 that "compression" logic is done better than in ver 4. The idea is very good.
>>Pro2 version 6 should be released soon.
Yeah, I'm looking forward to that, too. I participated in the Usability Test, it really looks great.
>>is there is no index supporting that FIND.
Yes, in v5 there is such an index. But why do you have thousands of records there? Usually replqueue does not have a large number of records. This sounds like you don't have enough replication processes as they can't handle your load. During the upgrade to v6, be sure to consider compression with split replication threading.
Usually the replqueue is very small or empty. However we are on Ver 4 where max number of threads is 5. Well, and DataServer license we have is 5 too.
Occasionally the volume of changes in one table (inventory of our goods) exceeds the capacity of 5 threads easily. It happens daily at most active business time 3-5 pm. And thus we have a backlog of on hour or two of that table changes. That backlog ( replqueue ) diminishes off hours and then the queue disappears completely. So we often have many thousands of records in replqueue table.
I will wait for version 6 to upgrade. Then we will use "trigger compression".
Is "trigger compression" done by default in ver 5 ( in ver 6 )?
>Is "trigger compression" done by default in ver 5 ( in ver 6 )?
There are several templates for different tasks, one of them is tplt_repltrig_with_compression.p. In the fourth version it seems there should be this template.
You only need to replace the standard template in DEL_TRIG_TEMPLATE and WRI_TRIG_TEMPLATE properties. And regenerate the Processor Library.
>However we are on Ver 4 where max number of threads is 5.
The maximum number of threads, including sub-threads, in v5 is 100. Of course, more than standart 5 threads require additional licenses for the DataServer.
My big client has almost all 100 threads involved. We have more performance benefits from this.
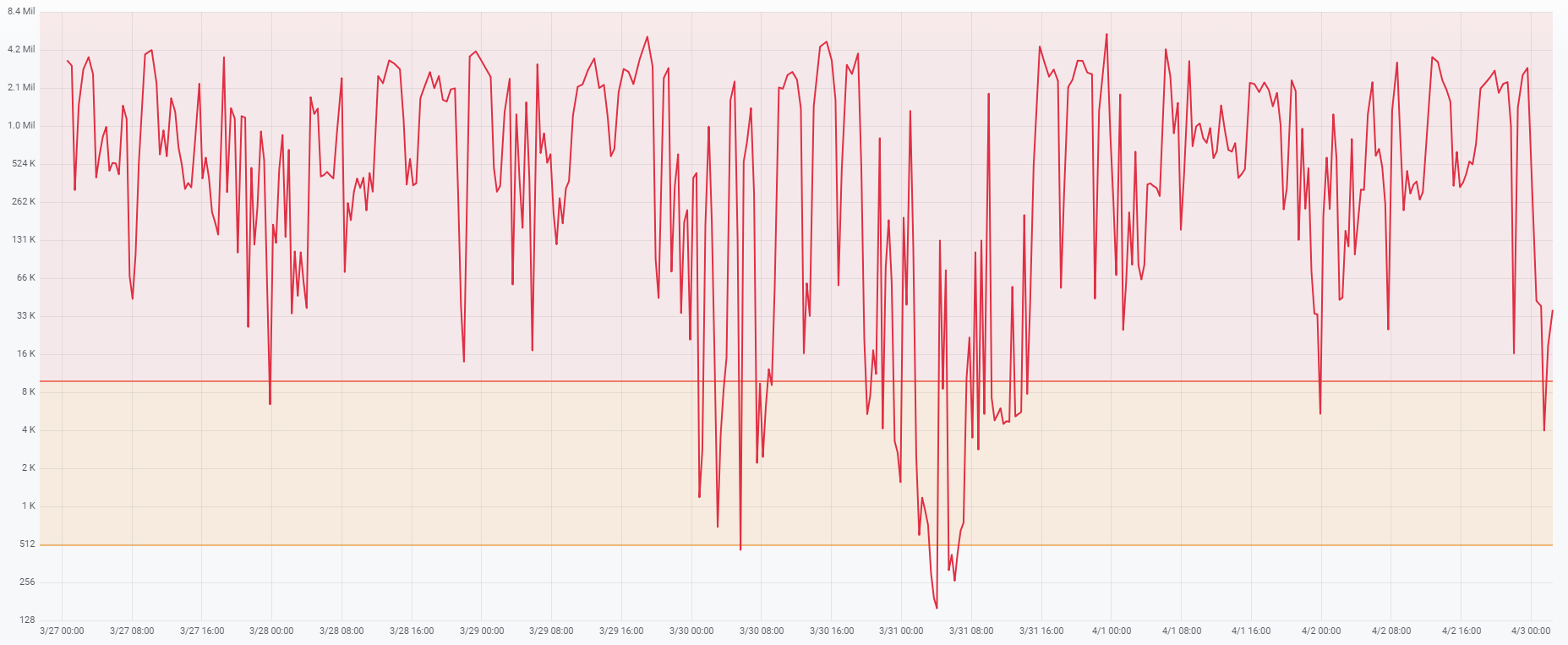
Next graph shows an example of the replication queue of a single process. This line forms the standard replication trigger without compression and without multithreading. Note that we are constantly in the red zone. This means that the size of the replication queue is almost always more than ten thousand changes notes, and on the graph we see several million notes in the queue. We've seen hours of gaps between Oracle and OpenEdge.
And next an example graph clearly shows how the performance of Pro2 has increased after the implementation of Compression triggers with the Split Replication Threads with up to ten sub-threads. We are moved to the green zone (no more that 500 change notes in the queues).
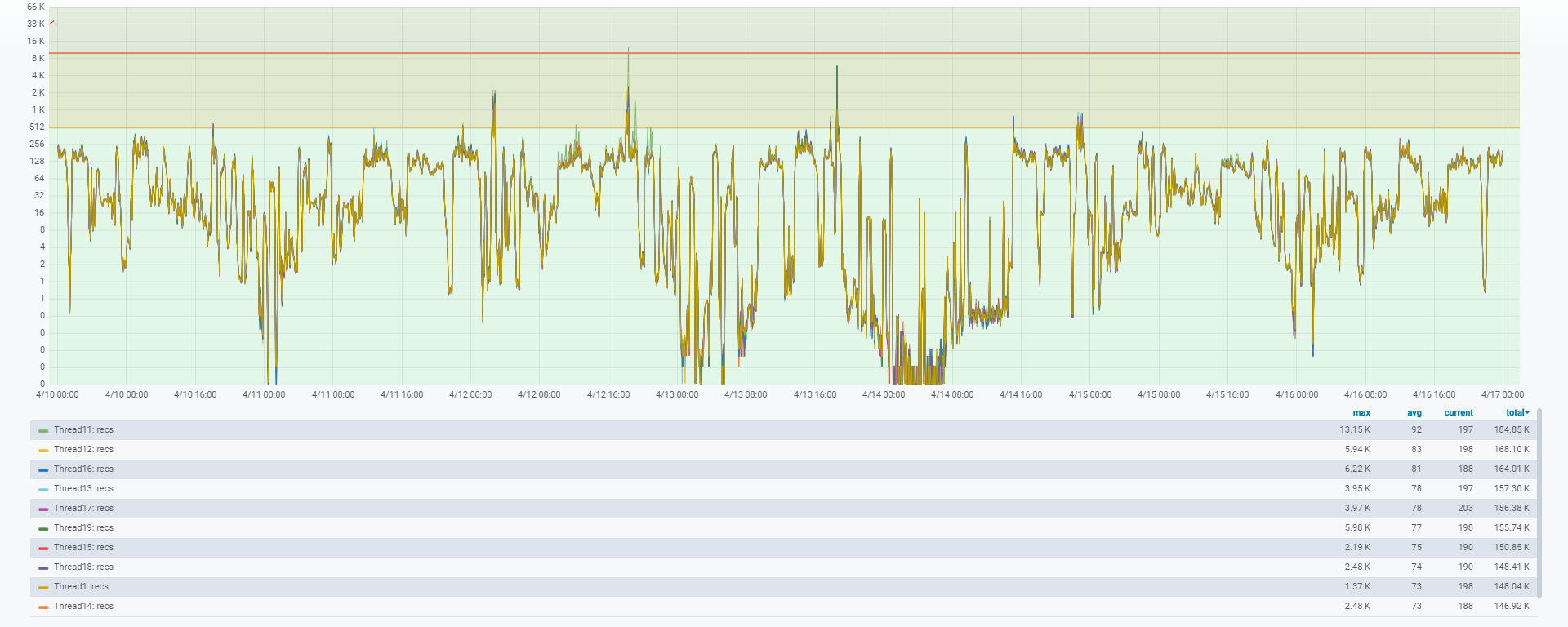
Now all the changes notes are evenly distributed between these sub-threads. The size of replication queues for each thread has decreased significantly. As result, the time taken to process replication notes was significantly reduced and the gap between Oracle and OpenEdge has almost been eliminated.
I will talk in detail about this on Friday at FinPUG 2019, as well as at the EMEA PUG Challenge if my session is approved there.
Update: Since I implemented "split replication threads" more than a month ago, I have not seen any locks.
( integer( RECID( table-name )) mod 10)
Thanks Valeriy.
You're welcome Dmitri!