
Pro2Oracle v.5.0
On windows machine works only Pro2 Admin panel.
Repl process, Bulk-Copy process and Schema Holder works on separate Unix server.
Source database works on separate Unix server.
Oracle works on separate Unix server.
Between them, a 10 Gigabit network.
When the Customer start the Bulk-Copy process (Primary sync with Oracle) only for one table, which size to small, something like 1.2 GB and 5 000 00 records, this take 2 minutes 45 second in average for each 100 000 records, even to load one table and no matter how many threads there are.
It is too long. The Customer have more large tables, which size more that 500 Gb up to 2 TB. It will take many months to sync.... even if we load table divided by years.
They Oracle DBA says, that he see that in Oracle for each records makes one commit when Bulk-Copy process work. And it is a problem.
He say, that this behavior in Pro2 application is wrong and it is needed to use more large transaction for improve performance.
I don't know how to do this in the Pro2.
So, my questions is:
1. How long time needed for load 100 000 records into your Oracle database?
2. If there is some special parameters for connect to Progress Data Server Schema Holder to improve performance (-DSRV)? Which parameters did you use? If ther is a parameter for transaction size?
3. If there is some special parameters in the Properies of Pro2 to make commit not for each records but, for examles, for each 1000 records?
4. Why Pro2 make comit for each records int the Bulk-Copy Process?
And last question about security. Why for Data Server for Oracle needs select permission for this system tables?
sys.argument$
sys.col$
sys.com$
sys.con$
sys.dual
sys.icol$
sys.ind$
sys.link$
sys.obj$
sys.procedure$
sys.seq$
sys.syn$
sys.tab$
sys.user$
sys.view$
sys.ts$
sys.ccol$
sys.cdef$
I had a very hard battle with their Oracle DBA to get these permissions. For what purposes need each of these tables for Data Server?
Or maybe Pro2 is not designed for such Big Data?
How do you solve this problem?
Regards,
Valeriy
Valeriy,
Sorry for the delay, but I could not find the original example of sending multiple bulk load source records per single target side transaction.
I did mock up a new example and placed it in the documents area of this forum. Please be aware that I performed very rudimentary testing to insure that with a proper setup, this example would copy multiple rows within a single target transaction. However I would not call it a fully tested or supported example. I'm simply attempting to provide you with a little insight into how Pro2 templates could be modified to support target side only features. Take my example and tweak it to meet the specific needs of your implementation.
You also might want to consider involving the Professional Services group to help you with this types of modifications, as they are fully experienced in helping with customized Pro2 setups. Your Progress salesrep can assist in getting those guys involved with your install.
Hope this helps,
Terry.
To answer the last question about security
"when you create or update a schema holder for an Oracle database, you must be able to connect to the database and have SELECT privileges on specific system objects. SELECT privileges on system objects are required because the Data Dictionary cannot access the Data Dictionary tables in the Oracle database without them; it must access those tables to create a schema holder"
Hello Valeriy,
Re. your Pro2-related questions:
1. How long time needed for load 100 000 records into your Oracle database?
I do not believe that we can say for sure - if I gave you a number then it would be specific to my system. Performance can vary system to system depending on the capabilities of the machines involved, the network, etc.
2. If there is some special parameters for connect to Progress Data Server Schema Holder to improve performance (-DSRV)? Which parameters did you use? If there is a parameter for transaction size?
No. A bulk load will comprise of a series of SQL INSERT statements; each record is inserted individually. You can run multi-thread bulk loads, but there is currently no real way to impact performance in this area on the product side.
3. If there is some special parameters in the Properties of Pro2 to make commit not for each records but, for example, for each 1000 records?
No.
4. Why Pro2 make commit for each record in the Bulk-Copy Process?
It is the way that the underlying DataServer works. Please feel free to log an Idea on the Progress Community if you would like to see this behaviour change.
I would recommend engaging Pro2 Services for further assistance. They can provide advice targeted to the specific environment.
Kind regards,
Rob
Hello Valeriy,
Let me try to answer your questions. In regards to privileges on the various sys* tables, Satya was correct in his reply that the privileges are necessary for the initial dataserver setup and for ongoing schema change support. There are several kbase articles that describe why are how the privileges get used.(For example see http://knowledgebase.progress.com/articles/Article/17082?q=sys.argument&l=en_US&c=Product_Group%3AOpenEdge&fs=Search&pn=1)
In regards to the bulk load process and changing the number of rows sent per Oracle transaction, this is very doable and is really one of the more powerful features of how Pro2 operates. You simply change the "template" file being used for the bulk-load procedure generation and code the scoping to work any way you see fit. Quite sometime ago, I think it was in Pro2 version 3.x, I wrote a special Oracle template that used the send-sql-statement to send a "--Bulk-insert Start" and a "--Bulk-insert End" to serve as a wrapper around the sending of many source side rows. You could even code the template to drop the data into ASCII files and use the Oracle command line bulk loader. This is an extremely fast load solution but in my experience as soon as you drop to ASCII you have to start fiddling with "weirdness" you might see in the data, NULL values, special characters, etc.
Let me startup a Pro2Oracle VM and I'll try to knock out a sample bulk load template that will give you some ideas of how to proceed.
The thing to remember is that by simply tweaking the default Pro2 templates, an end-user can very quickly put in play some pretty massive modifications to how bulk-load and replication procedures work. It really is one of the feature sets that often gets overlooked.
Hope this helps and stay tuned for a sample on how you could code this optional way of bulk loading.
Terry
Hello guys!
Thank you for your answers, it is very important for me.
I understand that Pro2 is a powerful and flexible tool.
From my side I also try to optimize the processes, but have not yet succeeded in this.
In the near future I will try to test ASCII load also.
Terry,
I will be grateful for the sample template.
Satya,
What do you mean by "pro2 triggers must be compression triggers" - I should use template "tplt_repltrig_with_compression.p" for generate triggers?
>each split counts as a separate dataserver license
Yes I know.
I also found an interesting article [View:http://knowledgebase.progress.com/articles/Article/P180901:550:50]
Where is it said
"Cause
The slow performance is contributed to by the WAN as well as by committing one record at a time to Oracle.
Resolution
Use BUFFER-COPY to create records in Oracle after the records are created in the ABL temp-table. This way Oracle will commit all the temp-table records at once."
I changed the standard code in this regard in the following way, but did not get an improvement, tell me what I did wrong?
DEFINE TEMP-TABLE tbl_PERSON LIKE bisquitsql.PERSON.
DEFINE BUFFER bfrSrcperson FOR bisquit.person.
DEFINE BUFFER bfrCpyPERSON FOR bisquitsql.PERSON.
DEFINE BUFFER bfrTgtPERSON FOR tbl_PERSON.
DEFINE VARIABLE strRecordID AS CHARACTER NO-UNDO.
DEFINE VARIABLE intRecordNum AS INTEGER NO-UNDO.
DEFINE STREAM stmTableLog.
OUTPUT STREAM stmTableLog TO VALUE("bprepl/repl_log/lmrbisquit_person.log") UNBUFFERED.
PUT STREAM stmTableLog UNFORMATTED
"Began Mass Replication on " STRING(TODAY,"99/99/99")
" at " STRING(TIME,"HH:MM:SS") SKIP.
FOR EACH bfrSrcperson NO-LOCK USE-INDEX class-code:
ASSIGN
strRecordID = (IF "NO" = "YES"
THEN UPPER("bisquit") ELSE "") +
STRING(ROWID(bfrSrcperson))
intRecordNum = intRecordNum + 1.
CREATE bfrTgtPERSON.
ASSIGN
bfrTgtPERSON.prrowid = strRecordID.
{bprepl/repl_inc/ibisquit_person.i}
ASSIGN
bfrTgtPERSON.Pro2SrcPDB = "bisquit"
bfrTgtPERSON.pro2created = NOW
bfrTgtPERSON.pro2modified = NOW NO-ERROR.
IF intRecordNum MODULO 100000 EQ 0 THEN
DO:
FOR EACH bfrTgtPERSON NO-LOCK:
BUFFER-COPY bfrTgtPERSON TO bfrCpyPERSON NO-ERROR.
END.
EMPTY TEMP-TABLE tbl_PERSON NO-ERROR.
PUT STREAM stmTableLog UNFORMATTED
"Processed " TRIM(STRING(intRecordNum,">>>,>>>,>>>,>>9"))
" records so far. Time is " STRING(TIME,"HH:MM:SS") "." SKIP.
END.
END.
PUT STREAM stmTableLog UNFORMATTED
"Finished Mass Replication at " STRING(TIME,"HH:MM:SS") "." SKIP
"Processed a total of " TRIM(STRING(intRecordNum,">>>,>>>,>>>,>>9"))
" records." SKIP.
OUTPUT STREAM stmTableLog CLOSE.
RETURN.>> What do you mean by "pro2 triggers must be compression triggers" - I should use template "tplt_repltrig_with_compression.p" for generate triggers?
Hi Satya,
I tried to use this feature "Pro2 has the ability to split 1 table across multiple threads".
I generated the replication triggers using a template "tplt_repltrig_with_compression.p".
Then I tried to start an additional replication process for thread 1.
But in the replrunning.log I received the following message:
Attempted to run ReplProc at 13:50:12 on 30/05/2017 for Thread # 1.
** ReplProc Thread 1 is already running in another session.
Somewhere there is a corresponding check for the second start of the process. How can I fix it? In other words, how to start the second replBatch process for the same thread when I use compression triggers?
Regards,
Valeriy
Valeriy,
Normally split threads are for regular replication, I don't know of anything written specifically to split bulk loads. Patty mentioned that she modified the generated bulk code for a customer so one bulk load starts with the first record and moves forward and another bulk load procedure starts with the last record and moves backwards, thus in effect creating 2 threads on 1 table. Theoretically, you could edit copies of the bulk copy code and use different date ranges if you have one on an index or use other options with other data.
We have not included the split thread code in replproc but have done it for customers as a custom fix. If you want to use split threading for normal replication and need to start multiple replbatch processes, you need to add more replcontrol records, one for each split e.g. 1-2, 1-3. Basically, we add an input from the batch file with the split number to match the new replcontrol record and a mod number. We then add code to replproc to check the sequence number against the mod to see which records to process.
Thanks,
Bryan
Hi Bryan,
Thank you for your reply!
>>Theoretically, you could edit copies of the bulk copy code and use different date ranges if you have one on an index or use other options with other data.
Yes, we do this for some tables, but unfortunately not for all tables this is possible. In addition, the tables are so big that even dividing the download by years, it's still too slow, since the DataServer makes a commit after loading each record into Oracle.
I also tried to use ASCII Load but did not succeed for Oracle (See more at: [View:https://community.progress.com/community_groups/openedge_pro2/f/248/t/33840:550:50])
>>If you want to use split threading for normal replication and need to start multiple replbatch processes, you need to add more replcontrol records, one for each split e.g. 1-2, 1-3. Basically, we add an input from the batch file with the split number to match the new replcontrol record and a mod number. We then add code to replproc to check the sequence number against the mod to see which records to process.
Could you describe this, please, in more detail how to implement it?
I created a record in replcontrol as follows:
CREATE ReplControl. ASSIGN ReplControl.GroupID = "PROCESS" ReplControl.CodeID = "REPLICATION" ReplControl.CodeVal1 = "1-2" ReplControl.CodeVal2 = "0" ReplControl.CodeVal3 = "0". CREATE ReplControl. ASSIGN ReplControl.GroupID = "CONTROL" ReplControl.CodeID = "REPLICATION" ReplControl.CodeVal1 = "1-2" ReplControl.CodeVal2 = "0" ReplControl.CodeVal3 = "1". CREATE ReplControl. ASSIGN ReplControl.GroupID = "LOGGING" ReplControl.CodeID = "LEVEL" ReplControl.CodeVal1 = "REPLICATION" ReplControl.CodeVal2 = "1-2" ReplControl.CodeVal3 = "2". CREATE ReplControl. ASSIGN ReplControl.GroupID = "QUEUE" ReplControl.CodeID = "DISPOSITION" ReplControl.CodeVal1 = "REPLICATION" ReplControl.CodeVal2 = "1-2" ReplControl.CodeVal3 = "D".
But it does not work (
When I start "replBatch.sh 1-2" where run this command:
$DLC/bin/mbpro -pf $PRO2PATH/bprepl/scripts/replProc.pf -p bprepl/RunReplProc.p -param "Thread="$1 >> $LOG
I get error int the $LOG file:
** Invalid character in numeric input 2. (76)
The same error appears in Pro2SQL Administration Utility also
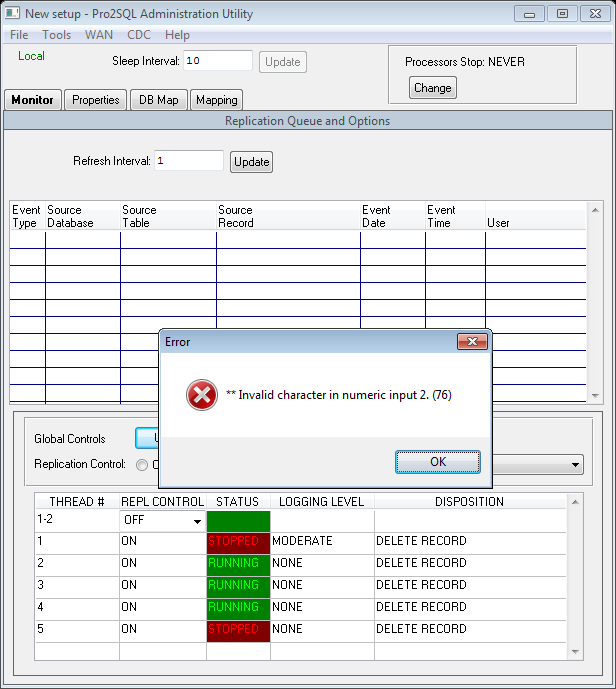
What did I do wrong?
Regards,
Valeriy
Valeriy,
Sorry for the delay, but I could not find the original example of sending multiple bulk load source records per single target side transaction.
I did mock up a new example and placed it in the documents area of this forum. Please be aware that I performed very rudimentary testing to insure that with a proper setup, this example would copy multiple rows within a single target transaction. However I would not call it a fully tested or supported example. I'm simply attempting to provide you with a little insight into how Pro2 templates could be modified to support target side only features. Take my example and tweak it to meet the specific needs of your implementation.
You also might want to consider involving the Professional Services group to help you with this types of modifications, as they are fully experienced in helping with customized Pro2 setups. Your Progress salesrep can assist in getting those guys involved with your install.
Hope this helps,
Terry.
Valeri,
We seem to have multiple topics going on within this thread and it doesn't appear ALL are related to bulk copy. If this doesn't answer your question, then you might want to start a new thread.
First...Bulk loading a table potentially can be split across "threads." I say potentially as really the index structure of the source table is the primary factor when determining if this is possible ,and really the piece to check is whether an index is already defined to logically break up the source side data. For example, is there a good date index that would allow multiple threads to properly bracket the reading of source data? Is the data separated by warehouse? Then threading makes sense, one thread per warehouse. This analysis really is the key to success when multi-threading the bulk load.
Pending that analysis is good and you have properly identified a good method of separation, then you simply pull up the generated bulk load procedure for the table(s) in question (normally to bprepl/repl_mproc), find how the generated procedure is navigating the source records (using standard templates this would be FOR EACH bfrSrcTABLENAME NO-LOCK:) and add a WHERE clause that makes sense based on the index evaluation done earlier. Save that modified version of the bulk load procedure to something like originalname1.p. Change the where clause again and again save it as originalname2.p sort of scheme. Then simply open a Pro2 editor session for each of the saved "threaded" procedures and run them individually.
Note**
If you wish to load other tables using the normal bulk load interface, then you should add the table being manually loaded to the bulk load "exclusion" list. This should make sense as you wouldn't want that process to also attempt to load the same table.
Be aware that "threading" a bulk load does NOT affect how replication handles the copy of data. Bulk Load threads and Replication threads are not the same thing.
Also you should know that splitting tables at the replication level requires a fully custom effort, as you have to change standard Pro2 code to traverse the ReplQueue table differently than normal. To split tables at replication also requires certain trigger dependencies, etc. so this really should be done by someone with experience in Pro2 implementations.
Hope this helps,
Terry
[quote user="temays"]
Valeriy,
Sorry for the delay, but I could not find the original example of sending multiple bulk load source records per single target side transaction.
I did mock up a new example and placed it in the documents area of this forum. Please be aware that I performed very rudimentary testing to insure that with a proper setup, this example would copy multiple rows within a single target transaction. However I would not call it a fully tested or supported example. I'm simply attempting to provide you with a little insight into how Pro2 templates could be modified to support target side only features. Take my example and tweak it to meet the specific needs of your implementation.
[/quote]
Thank you, Terry!
I will test this template and report the results
[quote user="temays"]
We seem to have multiple topics going on within this thread and it doesn't appear ALL are related to bulk copy. If this doesn't answer your question, then you might want to start a new thread.
[/quote]
I will create a separate topic for the performance of replication threads
[quote user="temays"]
First...Bulk loading a table potentially can be split across "threads." I say potentially as really the index structure of the source table is the primary factor when determining if this is possible ,and really the piece to check is whether an index is already defined to logically break up the source side data. For example, is there a good date index that would allow multiple threads to properly bracket the reading of source data? Is the data separated by warehouse? Then threading makes sense, one thread per warehouse. This analysis really is the key to success when multi-threading the bulk load.
Pending that analysis is good and you have properly identified a good method of separation, then you simply pull up the generated bulk load procedure for the table(s) in question (normally to bprepl/repl_mproc), find how the generated procedure is navigating the source records (using standard templates this would be FOR EACH bfrSrcTABLENAME NO-LOCK:) and add a WHERE clause that makes sense based on the index evaluation done earlier. Save that modified version of the bulk load procedure to something like originalname1.p. Change the where clause again and again save it as originalname2.p sort of scheme. Then simply open a Pro2 editor session for each of the saved "threaded" procedures and run them individually.
[/quote]
Yes, I know about it, and I did it. But the problem is still in the speed of loading into Oracle, because on the Oracle side for each record a separate commit is made.
For example. For loading 10 000 000 records in Oracle made 10 000 000 commit.
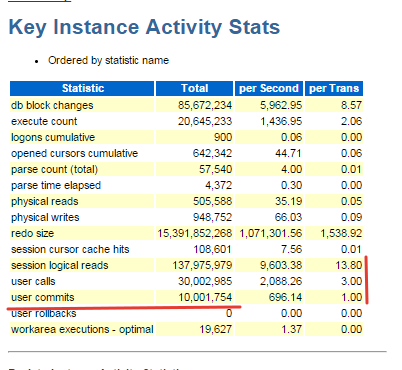
Today I will test your template and see how it will affect performance
[quote user="temays"]
Be aware that "threading" a bulk load does NOT affect how replication handles the copy of data. Bulk Load threads and Replication threads are not the same thing.
[/quote]
I understood it.
[quote user="temays"]
Also you should know that splitting tables at the replication level requires a fully custom effort, as you have to change standard Pro2 code to traverse the ReplQueue table differently than normal. To split tables at replication also requires certain trigger dependencies, etc. so this really should be done by someone with experience in Pro2 implementations.
[/quote]
As mentioned above, I used a template "tplt_repltrig_with_compression.p". I understand that it can be used to reduce the number of notes in the queue. This is especially important when the application performs massive data changes in a short period of time. For example, closing an operating day in the Bank.
Also, due to this, on one thread we can start multiple replication processes (1, 1-2, 1-3, etc.) - this is especially important for heavily loaded and often changing tables.
But as it is seen above, I could not do it. But we will discuss this in a separate topic.