
I've been playing with the use of SQLite as an embedded database. It is one of the most popular ones.
OE ABL uses local files in the session temp directory to store its temp-tables. I was just thinking how cool it would be if OE ABL had an option to keep its local TT files in SQLite instead of the proprietary format that it uses today.
...After filling the temp-tables with data from from the OE database, we would have tons of powerful options that we don't have today. Today we can obviously interact with the TT records from the ABL language (like they were OE database tables). But if the data was stored in a local SQLite database, then they you would also be able to run SQL queries against them, or transfer the connection to the database file to a different application in order to do follow-up analysis. This SQLite stuff performs very well, and a wide variety of other types of applications could use the results. (IE. the temp data would no longer be locked up within the context of a single ABL session, and wouldn't require marshalling to get the data out of the session .)
Its just a thought. I suspect Progress ABL is permanently married to its own format for temp-tables. It would be nice if other options were available. Even a simple alternative like having a ProDataSet:WriteSqliteDatabase() option would be super valuable (similar to WriteXml but sends it do a SQLite database to allow for subsequent SQL queries).
Thoughts? Is it possible to move forward with ideas like this in the OE ecosystem?
|
So how do you transfer data from OE to SQLite? Probably not directly within ABL, right (probably not even within the CLR bridge). It sounds like you probably make remote appserver calls or else you use SQL92 to get the OE data and push it into SQLite?
I'd like it if ABL could *directly* interact with a local SQLite database file, possibly even for hosting its own DS/TT.
Having an option to at least write to a SQLite db would be great. ProDataSet:WriteSqliteDatabase() option could also ease the integration of different technologies which most of us have for mobile use and other add-on products not using data directly from the OE DB. Currently we have SQLite DB in use with multiple mobile applications. The data is transferred to mobile devices in json format in normal online use and also stored in that format to SQLite DB for offline usage. Using either OE SQL write or SQLite.dll could open up some possibilities in app interaction. I'll be contacting you Roger for an example and give a thumbs up for dbeavon's idea.
-timo-
Hi Roger
It would be nice to have this uploaded on the oehive for example. Many of us would be interested I guess ;)
TIA
JC
or github :-)
or github :-)
or github :-)
or github :-)
There are a few nice things that could be gained by interacting with SQLite, and storing data from ABL. One is the ability to post-analyze the data using SQL queries. This is something that is pretty far outside the scope of anything we can do with ABL temp-tables. But another thing that could be gained is simply the ability to store a local, *persistent* copy of our data (eg. a copy that lives on a PASOE server ). I wonder if "persistence" is is something that could be added to the implementation of ABL temp-tables and prodatasets in ABL?
Before continuing to talk about "persistent" temp-tables, I should point out how costly it can be to read and process large amounts of OpenEdge data over client-server. For example, it takes a long time to read all of our open sales orders using an ABL business layer, and then combine them with related information from master tables (products, customers, salespersons, etc). The bulk of the cost can be attributed to the time-consuming network chatter that takes place between the ABL session and the remote database.
But what if the resulting temp-tables could be made *persistent* (shared) and copied between multiple ABL sessions within an msagent? That persistent data could be stored for whatever span of time is appropriate. These types of temp-tables could then be used as a type of cache, and would substantially improve performance for any clients of PASOE. Certain master tables (eg products, customers) might never need to be refreshed for an entire day - if the information was persistent and the source data was wasn't being actively modified .
In order to make temp-tables persistent, the best approach (today) is to serialize to disk (perhaps by using EXPORT statements or WriteXml). But this becomes expensive when a large amount of data is de-serialized because it needs to be parsed, and re-indexed, and re-loaded into the memory of every other ABL session that might need the same data.
Instead of jumping thru these hoops to perform serialization and deserialization, it would be more expedient if an ABL session could simply *attach* (bind) itself to some pre-existing temp-table files on the local SSD. This would give us a way to retrieve the costly client-server data only once - and then re-use it numerous times (by independent sessions in the msagent).
I see that there are startup options to preserve the temp files used by ABL sessions ... .
documentation.progress.com/.../index.html
... but I've never heard if there is a way to copy or reattach (bind) these files as static temp-tables in a new session.
Has anyone tried to accomplish something like this in ABL? This type of a feature would provide a subset of the benefits of an embedded database (like SQLite).
(PS. I think another approach for keeping persistent temp-table data might be to use "state-aware" sessions that hold onto their own temp data for long periods of time. Those would then serve up the data to other sessions as needed. The problem in this case is still the cost that is involved in marshalling data from the state-aware session to another session where the temp data would be reused. The marshalling would be costly. It would be much better if data would simply persist to local disk and anyone could attach to it instantly!)
There are a number of different issues floating around in here which I think are getting munged together at the expense of clarity.
You talk about the expense of sending a lot of data to the client. The usual solution for that is to do the assembly on the AppServer and then only send a limited amount of data over the wire.
Maybe I am old-fashioned, but I get a bit nervous around ideas like semi-persistent, although there architectures where one can do something like that safely. E.g., if one uses a distributed architecture with a tool like Sonic say Order Processing on one (or more) machines and Inventory on a different machine, then it can be useful to cache some inventory data on the OP machine to avoid excessive requests about the network. But, to do that one has to be careful in the design to commit anything that changes inventory to the inventory machine and, if possible, to provide Inventory with a signal that it can send to OP when some presumed relatively static information changes.
I can't say that the idea of accessing data with SQL is an attractive alternative to ABL.
Reconnecting to a prior session's TTs sounds like an EXTREMELY risky idea. How do you have any idea how current the data is?
Thomas, it sounds like you aren't quite sold yet on the idea of embedded databases - nor on keeping any persistent data outside of an OpenEdge database. But TT data is already being stored (cached locally) in a way that is similar to an embedded database... which is why I was trying to make some comparisons and suggest some improvements.
>> The usual solution for that is to do the assembly on the AppServer and then only send a limited amount of data over the wire.
No... because appserver *IS* over the wire. It is becoming more common to run an appserver on a machine that is different than the one hosting the database. PASOE is *NOT* considered to be an appendage of the database, or at least not as much as the "classic" appserver used to be.
It is more scalable and fault-tolerant to create a *separate* tier where you would run PASOE servers, preferably several of them behind a load-balancer. You might even want to run them in docker containers. This is especially feasible if your PASOE servers and database are running within the same LAN, connected by 10Gbit ethernet. Remember that a database server is there to serve a *different* purpose than an appserver. The first one serves raw data and the second one incorporates business rules as well. But we may want to create a new thread for a long discussion about software architecture.
>> send a limited amount of data over the wire
This is the goal for any database server. The OE database in version 12 is making improvements in this area by supporting "server-side" joins which promise to send less data over the wire (to appserver) than what needs to be sent today. Less data will be sent to appserver, and it will be up to the ABL business rules (in appserver) to determine what kind of data is subsequently composed and sent along to client applications.
>> Reconnecting to a prior session's TTs sounds like an EXTREMELY risky idea. How do you have any idea how current the data is?
How current is TT data supposed to be? 10 seconds? 10 milliseconds? The exact same risk applies to all temp table data after it has been created. This same risk applies to all types of caching as well. It is up to the implementation of the cache to expire whenever the source data changes, or after a reasonable timeout. Besides the risk is comparable to some of the other things we do in ABL on a regular basis. For example we make use of *tons* of data that is retrieved from the database using "NO-LOCK". That NO-LOCK data is very similar to a dirty cache and it can be just a "risky". (If you work with ABL long enough, you will have your own stories about the consequences of retrieving tons of data with NO-LOCK.)
I'm not suggesting that everyone should keep their TT data around all week or all day long. But it would be nice to have features that make temp-tables more flexible. As I mentioned before, the concept of temp-tables is not unique to ABL. Temp tables behave very similar to an embedded database (ie. like SQLite). Note that SQLite may be the most widely deployed database in the world*** and it would be extremely helpful to interoperate with something like that from ABL.
*** see sqlite.org/mostdeployed.html
> On Apr 28, 2019, at 3:48 PM, dbeavon wrote:
>
> I wonder if "persistence" is is something that could be added to the implementation of ABL temp-tables and prodatasets in ABL?
just use a dedicated local OpenEdge database for that.
> On Apr 28, 2019, at 3:48 PM, dbeavon wrote:
>
> It would be much better if data would simply persist to local disk and anyone could attach to it instantly!
yes. and you can do this quite easily with a separate OpenEdge database used for that purpose.=
Regarding the age of data in a temp-table, I see 3 main scenarios that need to be accounted for:
1) The data I am editing in my temp-table is out of sync from what is stored in the database.
2) The data I am editing is referencing other temp-table data that is out of sync with the the database (such as client-side validation data).
3) The user is making business decisions based on old data.
Scenario 1 is directly accounted for when using PASOE with business-entity-based classes with before imaging enabled. If the before image of your changes doesn't match the data in the database for the changed records, they will be rejected. Using data services with before imaging capabilities provides a lot of peace of mind regarding database integrity.
Scenario 2 encourages us to ensure that server-side validation is used for all data services/endpoints to protect the integrity of the database (don't rely on client-side validation).
Scenario 3 must be considered in the context of the application. Some things just aren't very critical. The more critical the decision to be made based on the data, the more important it is that the user knows exactly how old the data they are looking at is. Perhaps when the application is offline, a prominent timestamp is displayed showing the last time it was online.
Offline storage of data is really valuable for certain applications, but there are many approaches you may take depending on the application. Do you have a service/script running in the background of the application that's always checking for fresh data for the whole application? Do you always attempt a network call to the server and fall back on local data? How does the application know when it's back online to synchronize the offline changes? How do you handle conflicts when synchronizing?
We intend to work with offline/local storage in our web applications at some point, but I don't think we will need SQLite to access it. We are implementing an Angular + Kendo UI app with JSDO data services to a PASOE backend (based on business entity). In offline mode, I think we would instantiate the JSDO against the local files instead of the remote services, but the application itself would not need additional logic besides instantiating against local vs. remote data. That's how I anticipate it going anyway. I'm sure we will have some challenges, though.
Hi dbeavon,
Nice idea to persistent temp-tables to other databases :-)
We have been using Redis as a fast in-memory cache database. Every time a calculation is done, we check Redis first and only after not checking it, we do a calculation using temp-tables. Once we have done the calculation using temp-tables we push it into Redis. Works very fast and reliable. Only downside is that we have to install a seperate product.
I can't understand some of the "traditional" reasoning on the forum down the lines of "ABL can do it, why venture outside ABL". ABL and OE DB is very, very slow compared to some newer technologies for specific tasks. Using new and high-speed technology to compliment ABL isn't something to shy away from, it's almost mandatory to keep up with customer demands.
Given the highly specialised databases and other fast and cool solutions out there one can't expect ABL / OE DB to fill all those gaps.
>> use a dedicated local OpenEdge database for that.
I already am using a dedicated local database. The client-session TT's essentially act like like a dedicated local database. We interact with these temp-tables in virtually the same way we would interact with regular database tables. All we need are some minor enhancements (detach them, copy them, re-attach to other local sessions).
It seems to me that a few minor enhancements to temp-tables would involve far less overhead than setting up and managing some additional databases (and maintaining their persistent schema!). And it would probably be more likely that Progress would enhance their own temp-tables, rather than to start adding support for SQLite.
>> We have been using Redis as a fast in-memory cache database
I have only done a little bit of reading about redis. The challenge I often face is when I'm working with lots of data (eg. 100,000 rows in a handful of tables.) Progress would have to do substantial work when it comes to the serialization or marshalling of that data. I was hoping for a solution where 100,000 rows (and related indexes) would be instantly available for an ABL session to start using (as TT/DS data). It would be nice if the *only* work that needed to be done was to simply "attach" a client-session to the local data.
If we could "detach" from a client session's TT data and make a copy of the underlying file(s), then I would certainly consider storing that in redis for other ABL client sessions to use in the future - once they are ready to "attach" to it.
I gave an entire presentation on using CDC to offload data to (in that case) a MongoDB to realize all sorts of use cases which are typically not handled very well by relational databases (high speed caches, searching in compound JSON documents). If you have a traditional "system of record" which all of a sudden needs to drive a web frontend which needs to be up and running 24/7 without a risk to your back-office this may come in handy (to name something). Like Onno states, modern applications become more and more heterogeneous technology wise, with each technology handling what it is best suited for.
Anyone interested in having a conversation on this next week in Orlando?
Only over a beer (or two) :-)
I know that some people install appservers on separate boxes from the database, in part because it allows using cheaper boxes for all of the components ... but when I have asked people whose opinion I trusted in the past, there are obvious reasons not to do it. But, even if one does do it, one would think that one would work very hard to have a very high speed link between the DB box and the appserver box(es), much higher performance than going to the clients.
To be sure, there can be an issue of currency even with TTs ... that's the whole reason for the work one goes to for updates when the record is not locked during modification ... but it seems to me externalizing magnifies that risk greatly.
While before-image information takes care of the risk of making an inappropriate update, the more stale the data, the higher the risk of having an update rejected.
Ah, yes, Gus, I meant to mention this in my original post. Once upon a time before we had temp-tables, I had a reporting technique which would make a copy of an empty database containing some appropriate generic tables and attach to that DB before invoking the actual report body. The report body would then fill that DB as needed for the specific report, print the report based on the DB data, and return where the DB would be detached and deleted. But, one could certainly leave it around ... if that were actually a good idea.
Oh, and it isn't as if I have an absolute rule against not using other technologies ... these days, that would be positively silly. But, I do think there is something significant to be said for keeping logic in one place. One of the reasons I have always been against database triggers is that it puts the application logic in more than one place.
> On Apr 29, 2019, at 12:52 PM, Thomas Mercer-Hursh wrote:
>
> one would think that one would work very hard to have a very high speed link between the DB box and the appserver box(es)
one need not work too hard.
i made a test setup with 10 Gb ethernet between two server machines. cost less than $200 for two 2 port 10 GbE network cards, two SFP+ optic modules, and a fibre-optic cable
Of course, that still has to go through TCP/IP, but do you have any benchmarks to compare to shared memory ... recognizing that there are a zillion variables involved.
I have a talk on that topic at NEXT next week :)
The short answer: it depends. But client/server _can_ actually be faster than shared memory in cases where you are dealing with a set of records rather than individual finds. Which is mostly what this thread seems to be talking about.
So, the apparent conclusion would be that if one is tempted by cached local data because of the speed of getting things over the network, perhaps one just needs to make the network faster and then not have to worry about concurrency and the like?
Or maybe they really need cached data local. I think that was the original question...maybe I am wrong.
We NEED cached data local that will allow our tablet application to run independent of the server. This is why we use SQLite...
The data is only as old as the last time the tablet was connected to the server....
The original post seems kind of open ended. But I agree -- if you want an "offline" capability then temp-tables obviously aren't going to do the trick and sql-lite might be a suitable option. OTOH, WRITE-JSON and READ-JSON would also work without much trouble.
If you are "always connected" then even with a slow network there are quite a few things that can be done to improve performance and some of them are very effective. None of it should be a mystery but I am none the less often surprised to see how little awareness there is of the coding techniques and tuning options that are available and how well they can work.
>> just needs to make the network faster...
The limitation is about the network, but there is some complexity to it even so. Our network easily does 500 Mbps or 100,000 packets per second. But that doesn't translate directly into faster "client-server" code.
From what I can tell, the limitation is primarily in the OpenEdge implementation of client-server. The implementation will frequently slow us down to 2-3,000 records per second. The reason for the slowness is partly due to how "chatty" client/server can be (coordinating a lot of small units-of-work between client and server). And I've found that there is also an artificial CPU delay/bottleneck within the database servers - probably based on the way that it allocates CPU by time slice. If you watch cpu in glance, will often seen _mproapsv get capped out at a predictable, and premature limit (only 9% of a core) even though there is lots of outstanding work that is waiting to be done. ... and the other machine resources like disk and memory and network still have *plenty* of capacity (both on the client side and the server side).
As Tom mentioned the trick is to use sets of records (FOR-EACH-NO-LOCK). That will pull 10's of thousands of records per second from the database over a client-server connection. This is better than doing individual finds, and is one of the *ONLY* tricks we have available. It allows client-server to perform as well as shared-memory.
Which brings us to cache. This is yet another thing which could level the playing field. A local cache would allow us to instantly retrieve 10's of thousands of records directly from local storage. And we would then be able to create solutions that are just as fast on "client-server" as they are in "shared-memory". Detaching and re-attaching temp-tables is just one (ABL -centered) idea. But truthfully I'd prefer a solution based on SQLite, as long as it was easy to interoperate with it from ABL.
> On Apr 29, 2019, at 2:54 PM, dbeavon wrote:
>
> the trick is to use sets of records (FOR-EACH-NO-LOCK).
also, in recent releases, there are various tuning paramters that can improve client-server performance quite a lot compared with the defaults settings.
> On Apr 29, 2019, at 1:48 PM, Thomas Mercer-Hursh wrote:
>
> do you have any benchmarks to compare to shared memory
not yet for 10 GbE. but i have done comparisons of 1 GbE network client-server with shared memory and for some cases they are nearly equal.
> On Apr 29, 2019, at 2:54 PM, dbeavon wrote:
>
> I'd prefer a solution based on SQLite, as long as it was easy to interoperate with it from ABL
SQLite is witten C and the (quite good) code is public domain. it would not be too hard to make a 4GL API for it. even Tom Bascom could probably do it in his spare time :) :)
Quite aside from my hypothetical coding skills you're getting carried away assuming that I have "spare time"...
I'm told that the API for SQLite is approachable via the .Net CLR bridge as well. Of course that type of a solution would only work for ABL running on the Windows platform. ...
It would be *much* nicer to have Tom write us a native 4GL API that could be used from Linux as well as Windows. I'd suggest starting with methods such as ProDataSet:WriteSqliteDatabase and ProDataSet:ReadSqliteDatabase.
Oh, you want my "free time". That's different from "spare time" ;)
So, just for discussion, if the idea is to cache the data locally (disconnected or otherwise) and you are willing to have ProDataSets involved why wouldn't you simply use the existing READ/WRITE-JSON methods? What does SQLite buy you that READ/WRITE-JSON doesn't offer?
I wouldn't sweep "disconnected or otherwise" under the rug. Running disconnected is a requirement in some contexts and clearly many of those would benefit by DB support. Of course, how many of them are likely to be ABL code is another question. Whereas, looking for cached data in a connected client without first exploring tuning, hardware, etc. to improve performance is quite another ... particularly since, if the bulk of the processing is on the appserver, one can use a single high performance link between the appserver and the DB server and use the existing network for the connection to the client.
I'm not sweeping it under the rug and I do find it interesting but it does not seem to be the crux of the original post nor what David is (mostly) getting at. He keeps coming back to wanting some variation on "persistent temp tables" so I am wondering why an interface to SQLite is perceived to be more useful to him than READ/WRITE-JSON.
Understood ... I'm just trying to make sure that the real question is focused on. If the real question is performance, this caching issue is probably the wrong end of the stick. I suspect that there is a perception that SQLite would be ready to go, but the JSON approach would require load time.
>> why wouldn't you simply use the existing READ/WRITE-JSON methods
That is a good point about JSON. I'm going to have to re-test the performance of that. My recollection is that the deserialization from JSON took a several hundred milliseconds for 100,000 rows of data. At the time it wasn't fast enough for what I was doing and it somewhat defeated the purpose of the cache.
(As I recall, I had an active orders screen with several thousand order items on it. And I wanted to incorporate the product-master descriptions for each of the distinct products that was present in the order items. So I tried to deserialize the entire product master out of JSON into a product-master temp-table. This deserialization was quite a bit slower than what I needed. To make a long story short, it was faster to calculate the distinct products and use it to perform individual "find" operations against the remote database. I was disappointed by the inability to use a locally cached product-master, especially since it seems like a really good fit for keeping in cache, and a good fit for updating on an infrequent basis, eg. every ten minutes. It seems to me that it would have been cleaner to use the local cache, without placing an unnecessary burden on the remote database via client/server . But as things turned out, the overhead and complexity involved in deserializing a large product master - from JSON into a TT - was just enough to make that approach less desirable than simply relying on the source database).
I think the only reason the local JSON didn't quite work was because of the cpu requirements for deserializing and re-indexing the product master every time that cached data was needed by a new ABL session. Perhaps things would have worked better if the number or records was < 10,000 rows instead of ~100,000. But as the quantity of cached data decreases, it also eliminates the motivation for having a local cache in the first place!
The best kind of local cache is something that wouldn't need to be deserialized and re-indexed prior to using it. It should be a matter of detaching/attaching (ie. there shouldn't be so much preparation work in order to use the cache).
Note that my request for ProDataSet:ReadSqliteDatabase would also have an overhead penalty, but hopefully not as much as JSON since the format would be binary on both sides. ... Furthermore (and don't tell anyone this) but the request to have a ProDataSet:ReadSqliteDatabase is just the initial step towards something better. What I *really* want is a client-session startup parameter which specifies that all temp-table data in ABL will be entirely hosted in an embedded SQLite database. That would allow us to totally eliminate serialization and deserialization overhead in ABL sessions.
> On Apr 29, 2019, at 6:14 PM, dbeavon wrote:
>
> hopefully not as much as JSON since the format would be binary on both sides
not the same binary format, so decoding from source format and recoding to target format and vice versa would still be required. and there is indexing overhead on the SQLite side. and query processing overhead to retrieve stuff. and locking and other stuff. no free lunch, folks.
> So I tried to deserialize the entire product master out of JSON into a product-master temp-table. This deserialization was quite a bit slower than what I needed.
Just curious, was your temp-table memory-resident? Or did that involve DBI I/O?
> not yet for 10 GbE. but i have done comparisons of 1 GbE network client-server with shared memory and for some cases they are nearly equal.
We have used dedicated 10GbE links between appserver & db for a while while waiting for a new server that could handle all our load (that was with 11.3 and about 2 years ago.) After heavy tuning, including large package sizes in both TCP & ABL we managed to get queries that return large result sets to work as fast as shared memory, but like others have said, as soon as you have to do lots of find firsts the performance drops dramatically. As a result our appserver request duration on production workloads was about 3 times higher on the networked appserver compared to the shared memory appserver.
>> about 3 times higher on the networked appserver
hmmm... You say 3 times higher, and Progress claims there will be a 300% improvement after fixing "client/server" connectivity in the OE 12 database servers (now with support for threading and joins). That seems very coincidental. Perhaps they are using your numbers to predict the potential performance improvements that their customers will experience.
I'd guess that any ABL code which uses thousands of "find firsts" will NOT see a 300% overall improvement, even if the bottleneck is entirely due to the database. And moreover it seems hard to believe that they can predict that kind of improvement in real-world applications. I haven't seen OpenEdge v.12 in action myself, but I'll be very relieved if it gives us a 50% improvement, let alone 300%.
I may be a bit cynical but it seems the only way you can guarantee that someone will see a substantial performance improvement is if you were removing a "pause" statement from the original code. ;-)
@jankeir can you please tell me what you've done (in 11.3) to improve the performance for nested loops? (eg. for each order, each order line)? Do you try to break those apart into separate & independent FOR-EACH-NO-LOCK operations? Otherwise in the case of the nested FOR-EACH it seems that the client/server performance degradation is more dramatic and is proportional to the number of orders.
> On Apr 30, 2019, at 9:09 AM, dbeavon wrote:
>
> it seems hard to believe that they can predict that kind of improvement in real-world applications
marketing people are astoundingly good at making predictions
>> was your temp-table memory-resident? Or did that involve DBI I/O?
I suspect it was NOT memory-resident but I didn't get that deep in my investigation. Are there VST's for that? Or do I have to enable ABL tracing? Or maybe I just need to watch for file i/o in my temp directory?
If I had to guess, it was probably using I/O on disk (local SSD) considering the number of records. But I've never seen the local SSD become a bottleneck for an ABL database applications. Usually the bottlenecks in an ABL client-session are related to waiting on round-trips from the database, or using a single CPU core.
Not to rain on marketing's parade but the whole point of the SSJ stuff is to improve "queries". FIND statements are not part of that. The initial roll out is for static FOR EACH statements but I expect that dynamic statements won't be far behind.
Also -- the 300% was the sum of multiple enhancements. Most real-world scenarios probably won't take advantage of all of them simultaneously very often. Those that *do* will be very impressive though.
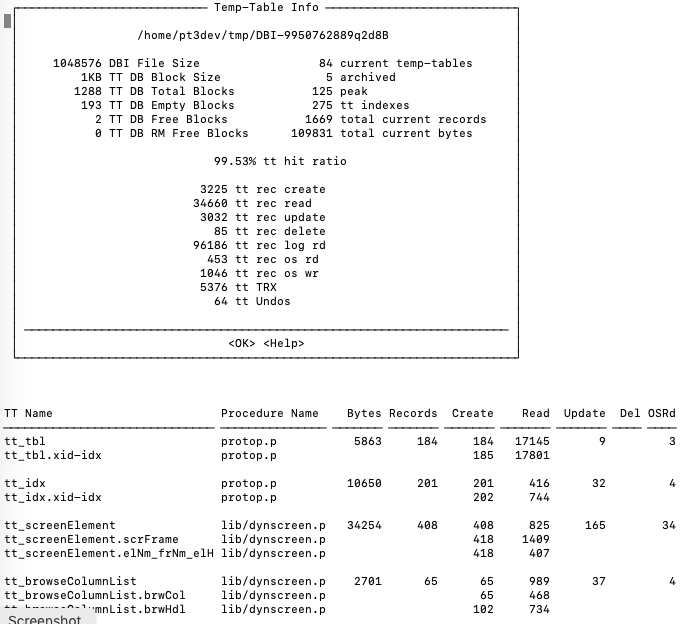
For temp-table activity there are some sort of VSTs that are private to the session (thus you cannot collect this from outside the session) and there is a class library to work with. ProTop has some sample code available that you can see in action via the ^t command. The code itself is in lib/ttinfo.p. You do need to set some session startup parameters to be able to collect all of the temp-table data.
> I suspect it was NOT memory-resident but I didn't get that deep in my investigation. Are there VST's for that? Or do I have to enable ABL tracing? Or maybe I just need to watch for file i/o in my temp directory?
I haven't played with the TT VSTs yet so I can't help you there. There might be some useful info in the client log if you enable TT log entry types. At a minimum, look at the DBI file I/O and size, though you'd have to know your code to know whether any I/O is due to the use of one temp-table versus another.
I haven't made any serious attempt to benchmark temp-tables but I've generally found them to be speedy enough when memory-resident. But even if -T is on fancy SSDs, that will be a *lot* slower than having temp-tables entirely in RAM. So I suggest you prove to yourself that you have optimized them for your data before deciding that temp-tables are too slow.
Also a quick reminder:
Temp-tables have their own buffer pool, which you can size with the -Bt & -tmpbsize parameters. That defaults to 255 blocks of 4k, so that's 4k short of a megabyte.
If you are going to cache large-ish sets of data in temp-tables, you really want to increase that by a large margin.
You don't really need VSTs. Just use the session options to show the files in the temp directory and leave them around after execution. They will either have nominal size, meaning everything is happening in memory, or not, which means that swapping is involved. If the latter, there are a couple of simple startup parameters to control the amount of memory available for TTs. I wouldn't be surprised if you found a little playing with those would have a profound effect.
"leave them around after execution" requires that you use -t and then crash the session. George can explain how to turn the resulting file into a hacked database but that isn't something that most people are going to know how to do. So you mostly end up seeing the file size.
Whereas the TT "vst" info and the supporting class library give you relatively easy access to a wealth of useful insight. For instance:
Thank goodness this forum is so well suited to posting technically oriented content!
Gus said:
>> use a dedicated local OpenEdge database for that.
dbeavon said:
> I already am using a dedicated local database. The client-session TT's essentially act like a dedicated local database.
Suggesting improved functionality is always fun. That's my favorite pass-time too. Like being able to reconnect temp-tables. It could be interesting to make the handling of temp-tables and regular databases more alike, so you could create tables in a local permanent database from within ABL code as easily as temp-tables today. And why not also make it possible to dynamically create new (or temporary) tables inside a regular permanent database using similar ABL code as we have today for temp-tables? (Rather then explicitly manipulating schema tables.) And then it would just be a matter of design choice whether any particular table would be permanent or temporary and whether it would be stored locally or in any particular permanent database.
However, I guess any such improvements would take a couple of years to get delivered, even if accepted.
Adding built-in functionality for SQLite would be even further off, I guess.
(But trying to build on the suggestions for implementing some interface to SQLite in custom code would seem attainable.)
But I don't see that you have told us any reason why you don't just set up an extra local OpenEdge database on each server, to use in stead of your temp-tables? (As long as it is intended for use on servers as you described it, and not on clients.) You could still have your main database on another server. This seems to be the solution that would be recommended within the current set of tooling available. Sometime you have to choose to use the tools that are actually already available and working well, rather than trying to "fight the system" to force it into working the way you (or I) would like it to work in an ideal world. (My experience is that fighting the system is rarely worth it. Except for those occasions when you find some loophole that actually works well.)
Also, I would not expect Progress to take any interrest in these suggestions without even being provided with any such reason as to why the current facilities are insufficient…
>> I don't see that you have told us any reason why you don't just set up an extra local OpenEdge database on each server, to use instead of your temp-tables?
Why not more OE databases? That involves lots of overhead/infrastructure, persistent schema, security considerations, licensing, etc. SQLite is free of any these considerations.
Moreover, with SQLite-based temp tables you would get some additional benefits that I had mentioned:
Getting large amounts of OpenEdge data to move from one tier to another can be expensive. Depending on how the ABL is written, this can be more expensive for "client/server", than when using the SQL92 driver. But after that initial expensive is paid, then SQLite-based temp tables can "preserve" the investment, and retain data for later use. The data could be portable, flexible, and far less "transient" than normal TT data which is immediately lost after the client session ends.
