
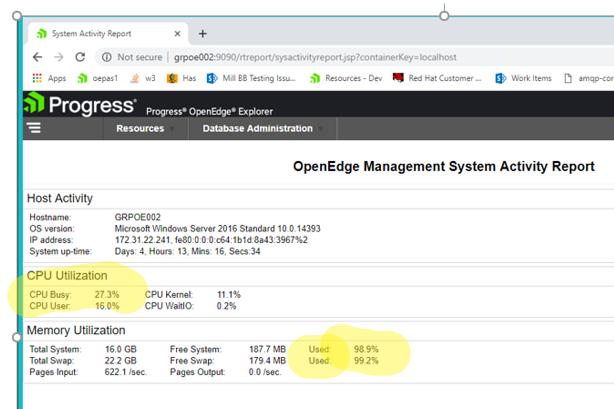
Is there a way to set a cap on the memory that may be allocated by _mproapsv? See screenshots below. I'd rather the agent process just die after getting above 8 GB or so. Otherwise the entire server became unstable. This happened after all available memory and swap was consumed. This was on Windows Server.
I will also be changing the number of "abl sessions per agent" but that is only part of the problem. Based on my observations, it was just 2-3 misbehaving sessions that caused the memory usage to grow to this point!
As you can see, a single PASOE ms-agent consumed over 10 GB. It was so high that OEE needed to display the memory of the agent as an exponent (1.02E7) KB!
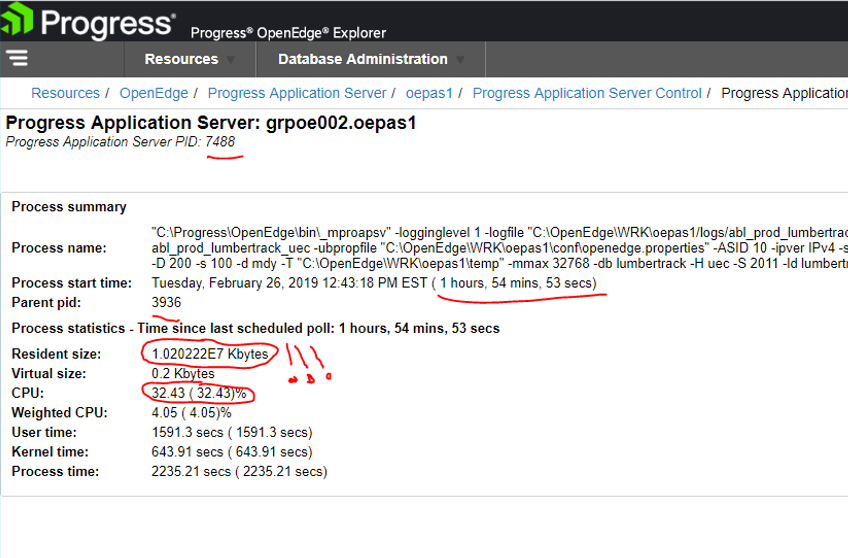
Seems that KB isn't the best for displaying thesevalues. I'll log an issue for that. As for memory usage... Have you looked for memory leaks in your app? You can fetch stacks and in memory objects for each session from the agents page in OEM. If you care to poke through the REST API for /oemanager there is a more detailed set of results you can fetch.
A couple of kbases for your reading pleasure.
knowledgebase.progress.com/.../Detect-PASOE-memory-leaks-with-Dynamic-Objects-Logging
If you're on a recent 11.7 version, then this is more helpful. No support in OEM for this yet.
knowledgebase.progress.com/.../New-ABL-Objects-Tracking-REST-API-under-PASOE
There are some other discussions on this here on communities.
With regards the OEM behavior where the resident size of the process is shown as an exponential factor, I have noted this down as a bug which will be planned and addressed in a future release. The Process Summary page in general can do with an improvement.
I didn't see any way in the PASOE configuration to put a cap on the memory utilization of a multi-session agent process. Am I missing something?
In our case, I think the problem is related to a certain analysis-report that is pulling *tons* of data into memory-resident Temp-Tables. (It isn't a "leak" as such.) I suspect it is related to the fact that the user was too greedy in their time period selection (probably pulling *all* data for a month or year). Since we have so many reports that are moving into PASOE, it is hard to micro-manage the memory utilization of each.
I'm not 100% sure of the reason for the memory consumption. But on a general basis, I think it would be better if the "ms-agent" could enforce a memory restriction. Any of our reports that needed more memory would die, rather than cause the entire server to become unstable. Hope this is clear.
We are migrating our reports from an HP-UX server that had almost 400 GB of physical RAM! And the "classic" appservers could take as much as they wanted.
There isn't a size limit setting for PASOE on agent memory consumption. I'll pass along this thread to the right team.
Here is another one from today.
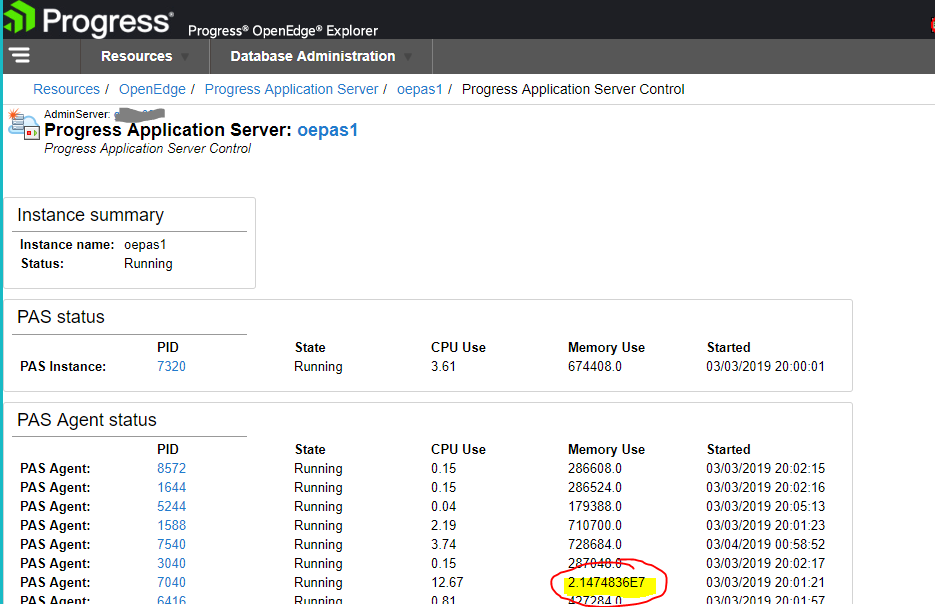
According to my scientific calculator, this comes out to ~21.5 GB (out of 32). And the memory is in the process working-set (actually resident).
According to OEE, this resident memory is NOT reported as part of the ABL session memory, here are the four affected ABL sessions:
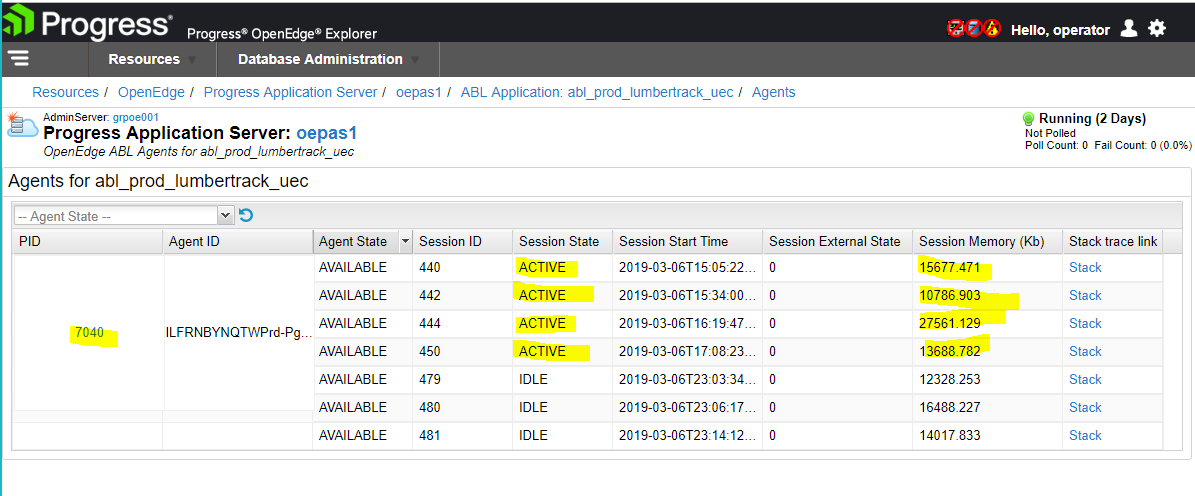
So the memory appears to be port of the process, but not part of the only four sessions which are the most likely consumers of the memory (these are four long-running SSRS-shipping-analysis-reports that I've highlighted above). I'm able to free memory if I use the tomcat "manager" app and expire the HTTP sessions.
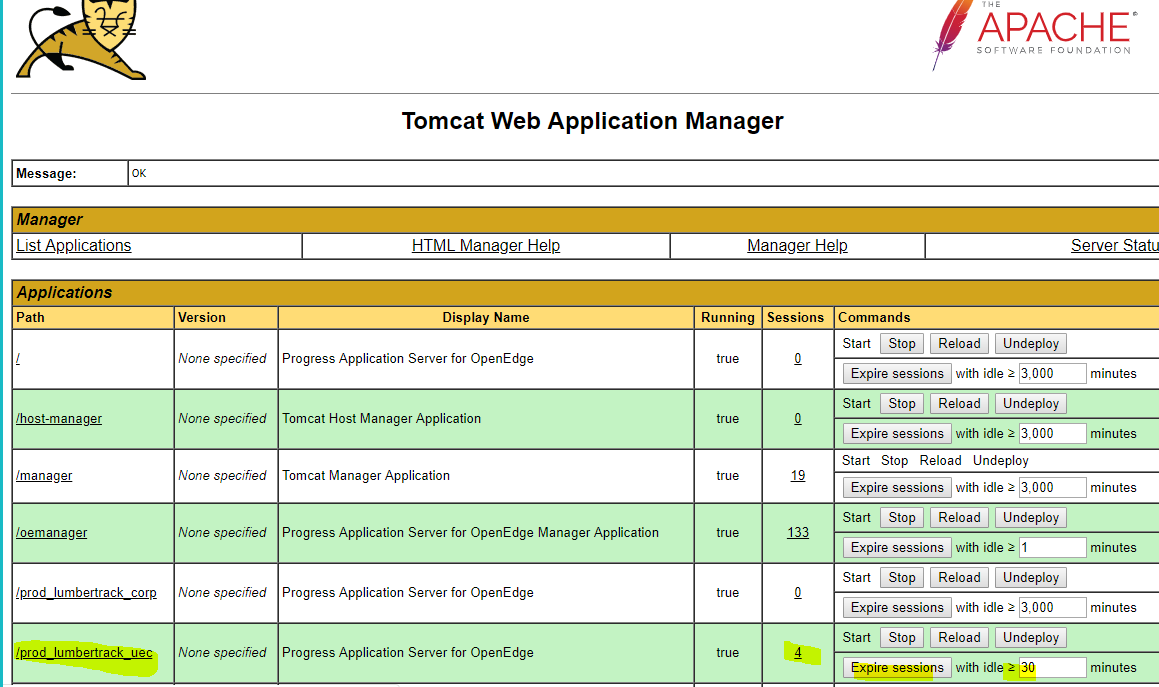
After doing that we see the following in the logs (times four), and the ABL sessions are terminated, and the memory is released:
[19/03/06@18:52:45.196-0500] P-007040 T-002576 1 AS-450 -- Connection failure for host 172.31.22.240 port 64579 transport TCP. (9407) [19/03/06@18:52:45.196-0500] P-007040 T-002576 1 AS-450 MSAS Error handling request! Status=-4004 [19/03/06@19:01:29.557-0500] P-007040 T-002576 1 AS-Aux-0 MSAS Worker Thread exiting. Number: 7, Status: -14
Unfortunately it would take a whole day for these HTTP sessions to have expired on their own. That is because the tomcat HTTP session timeout in the default web.xml doesn't expire sessions until 24 hours have passed. Side note - This is to avoid an unrelated bug in the Progress openclient where session-free connections are closed prematurely (https://knowledgebase.progress.com/articles/Article/pasoe-failures-after-a-period-of-inactivity )
Perhaps I should be looking at overriding the HTTP session timeout at the level of an individual webapp. If that were possible then the HTTP sessions which are used for SSRS-shipping-analysis-reports could be given a shorter session timeout then the ones that are used for the openclient session-free connections in .Net.
I believe the place to override the HTTP session timeout for individual webapps is in the file at the path : oepas1/webapps/myreportingapp1/WEB-INF/web.xml. I guess I will start playing with the timeout in there and see if I can cause my SSRS-shipping-analysis-reports to properly time-out, without breaking my openclient session-free connections. Please let me know if I'm not on the right track. I guess another approach would be to use STOP-AFTER in the ABL of the report itself but I'm not crazy about starting down that road yet.
From ABL code is there a way to gain access to the related HTTP session that is provided by tomcat?
For example, could I dynamically change the HTTP session timeout for a given appserver procedure . I would like some procedures to have shorter HTTP session timeouts than others. This would only be needed for certain unusual and long-running reporting procedures.
Here is a link to show that webapps can do it directly from java.
stackoverflow.com/.../how-to-set-session-timeout-dynamically-in-java-web-applications
(It appears they can use the setMaxInactiveInterval - tomcat.apache.org/.../HttpSession.html ).
I have not found a way to interact with the HTTP session directly (from ABL code). The only thing I found was some read-only properties (Progress.Lang.OERequestInfo ) that are accessible from SESSION:CURRENT-REQUEST-INFO .
> On Mar 6, 2019, at 7:36 PM, dbeavon wrote:
>
> this comes out to ~21.5 GB
2147836 is a familiar string of digits.
two to the 31 power is 2147483648
i bet there is a computation error of some sort and an overflow or other error has occurred.
>>computation error of some sort
No that isn't a computation error. I watched the windows perfmon counters rise to that in a real-time graph.
Next time I'll take a memory dump and send the 20 GB file over to Progress. ;)
What bothers me is that the memory isn't listed in the ABL sessions that are running this "SSRS-shipping-analysis-report". As near as I can tell, the report is pulling in 10,000,000 rows of data from the database, and storing these into a temp-table. This is bad enough but the moment that the whole mess is serialized and sent back to APSV client, it immediately doubles the memory usage (in a span of 30 seconds it consumes about 10 more GB).
This is not a well-designed workflow to say the least. But it poses some interesting questions about how to manage & monitor PASOE when the code is poorly written (yes, it happens).
It seems fairly clear that the TT/DS memory usage is *excluded* from the "session memory (KB)" in the OEE console. Perhaps there should be another column that shows the current TT/DS data size. It isn't an interesting number in itself until the AVM decides it needs to pull it all into memory at once (eg. for whatever reason, like scanning it on a different index, or serializing it back to the remote APSV client). When that happens it seems to "dim the lights".
Please let me know if there is any easy way to monitor the ongoing TT/DS memory activity of a session at a high level. I might use logical disk counters in perfmon. That is a round-about approach - it would be nice if OEE or ABL had a metric for the amount of TT/DS data in use by a session. I found a whole whitepaper on this but it looks like it gets down to an extremely fine level of detail, which I don't really need:
www.pugchallenge.eu/.../temp-tables-pug-emea-nov-2017_v4--dan-foreman.pdf
temp-tables do not use an unbounded amount of memory. they have a fixed-allocation in-memory buffer pool and on-disk backing store. once the temp-table page buffers have been allocated they don't grow further. record buffers and related structures are allocated in the 4GL run time but typically are relatively small. usually there are one or two per table, depedning on the 4GL code.
but it sure sounds like something is wrong in your situation. maybe tech support can assist.
how large does the .DBI file grow when this problem occurs ?
Gus, thanks for the feedback. I definitely didn't expect that the TT/DS data would cause these memory problems. But nevertheless the memory problems are happening simultaneously with the execution of a very big report.
As you say, the TT/DS'es should be backed by disk, but there may still be moments when large portions need to become memory resident like when serializing it back to the remote APSV client.
I already have a memory leak reported on 11.7.4 (with a full reproducible; it is waiting on a hotfix or service pack from PSC-DEV). I may wait for that to be finished so I don't muddy the water too much. I think tech support has had a backlog with PSC-DEV since they've been so busy working on OE 12.
are XML documents or JSON structures part of the reporting process? sometimes entire XML documents are kept in memory temporarily (depending on whether or not you use the SAX parser).
No, not intentionally. I just assumed that as the data is serialized back to the APSV client, a very large portion would be loaded into memory.
The openclient uses APSV proxies that directly reference the DS and TT structures.
>> There isn't a size limit setting for PASOE on agent memory consumption. I'll pass along this thread to the right team.
Did this idea ever go anywhere? I think it is reasonable to put constraints on the memory usage in _mproapsv. It is unreasonable to allow those crazy processes to grow indefinitely. We should be able to ask PASOE to put an upper limit on the memory that can be consumed. It surprises me that there isn't yet any configuration for this type of thing - considering the persistent leaks.
In OE v.11.7.4 we had encountered a memory leak and created a repro and sent it to Progress and they supposedly fixed it. But we still see a few hundred MB leaking out of certain _mproapsv's every day, even now that we've upgraded to the "fixed" version 11.7.5. I knew that there would still be some level of a leakage, but did not expect it to be 100's of MB per day. It is pretty disappointing considering the amount of effort that is involved on our end to help Progress to fix these memory issues.
Maybe most PASOE customers consider this to be an acceptable amount of memory to leak? Has anyone else observed steady leaks of msagents on Windows or Linux?
I'd love it if Progress would really take ownership of this problem. Perhaps they could review memory dumps for anyone affected.... Ideally we would just wait for the process to grow to a certain size, say 2 or 3 GB, then we'd trim all the ABL sessions out of it (analogous to a "freshly started" _mproapsv). Then we'd take a memory dump of it, zip it up, and send it over to Progress. I'd guess that someone over there would be able to crack that thing open and figure out what the actual contents are. Unfortunately Progress doesn't seem eager to offer this service.
In fairness, I believe there are some REST interfaces to extract certain diagnostic details about the contents of the msagent memory. But they only work with memory that is currently "associated" with the current ABL sessions (lets call this "managed" memory for lack of a better term). However in our case we've observed that we can trim *every* single ABL session from the msagent process and the committed memory size does not decrease (ie. the leak seems to be happening outside of "managed" memory).
Aside from the CLR bridge we do not use anything but normal memory that is "managed" within an ABL session. IE we are *not* using ActiveX, COM-HANDLEs, MEMPTRs or whatever. (I will review managed memory in the bridge once again, but that has never turned out to be a significant source of our leaks).
Are there other PASOE customers who are still struggling with runaway memory (100s of MB per day)? It would be nice to hear how you are dealing with it. Personally I think that a memory constraint in PASOE is a reasonable feature, considering how challenging it is to plug all the memory leaks. Basically it would work in a way that is analogous to a "resource timeout" but would kill off the agent after its memory size reached an excessive level (maybe 2 or 3 GB). This is a configuration that could be enabled by *default* for every customer (especially if it was set high enough, say 30 GB or whatever ;-).
>> Did this idea ever go anywhere? I think it is reasonable to put constraints on the memory usage in _mproapsv. It is unreasonable to allow those crazy processes to >> grow indefinitely. We should be able to ask PASOE to put an upper limit on the memory that can be consumed. It surprises me that there isn't yet any configuration >> for this type of thing - considering the persistent leaks.
This is a good suggestion. Putting constraints on the memory usage in _mproapsv would help on situations of runaway memory.
In the last year, I have been playing with Kubernetes running PASOE as a container.
Kubernetes has a readiness probe and liveness probe functionality. The readiness probe tells that the container is available for access and the liveness probe tells whether it is unresponsive and needs to be re-started.
Perhaps, a possible approach, if you use Kubernetes, would be to define a readiness probe and a liveness probe to detect when the memory usage reaches a certain limit, tell Kubernetes that the container is no longer available and that it needs to be re-started. This can be done in a way that ensures that the current transaction is completed.
Have you run PASOE with Docker and Kubernetes?
What do you think of this possible approach?
I hope this helps.
We are predominantly using Windows infrastructure. I'm waiting for PASOE docker containers to come to Windows.
I'm very eager for that. I think the hold-up is that Progress still needs to certify PASOE on "windows core". Here are the discussions and the KB:
community.progress.com/.../36953
community.progress.com/.../38719
community.progress.com/.../37317
knowledgebase.progress.com/.../000041790
Alternatively we could probably use LCOW or something like that for hosting PASOE by itself in a Linux OS which is dedicated to PASOE:
docs.microsoft.com/.../linux-containers
But we'd lose quite a lot if we ever had to move PASOE over to Linux. On Windows we can use the "CLR bridge" and this essentially gives us most of the libraries/packages that we need in the .Net ecosystem. It all works in-process within the msagents and is very fast. We use it for REST, LDAP, FTP, Newtonsoft JSON, XML DOM, XPATH queries, ODBC queries, emailing, system.diagnostics.process, and much more! The syntax for using the CLR bridge takes a bit of effort, but the functionality is what matters. Before moving to Windows from HPUX, many of these types of things had to somehow funnel thru OS-COMMAND or UNIX or whatever. That approach leaves a lot to be desired.
Back to the memory issues.... Given the continual growth of memory, I think it is safe to say that the _mproapsv's would eventually crash one way or the other. Nobody lives forever. If we simply used an external task to kill them the _mproapsv's after they reached 5 GB then that would also solve the problem too! (And more importantly prevent a system-wide emergency.) PASOE seems pretty resilient to the death of its msagents. The only problem is the possibility that there will be sessions that are active at the moment of death. The related PASOE clients would receive an unfriendly communication failure and the database transactions would be rolled back. To avoid that problem we could take that server out of the load-balancer ("gracefully") and wait for the activity to subside before killing the _mproapsv.
We've discussed the use of load-balancers, scheduled tasks, docker, and kubernetes, and/or manual intervention. This is all a bit overkill for solving this simple problem. PASOE itself could very easily mark the msagent process with a "contaminated" / "do-not-use" flag - and then launch another new process in the ABL application to take over for the future client requests. Once the msagents with the "contaminated" flag had only IDLE sessions in them ... then PASOE could finally kill those process, (in a way that is similar to what it does with the "resource timeout" that it has today.)
We are waiting for PASOE docker containers on windows as well....