
We have some build automation tools that create an empty OE database, prior to compiling ABL code. It starts with a df file (or files) that contains all the desired target database schema.
One problem I've noticed in the automatic build operations is that the creation of an empty database is a bit slow. Are there any tricks to improving performance (possibly loading certain segments of the the schema concurrently on separate threads)? When the schema is loading, it seems that the operation is CPU-bound, on a single CPU core. I had first expected to find that disk would be the bottleneck, but that doesn't appear to be the case.
I'm also taking a peak at PCT in github and it looks like it relies on prodict/dump_df.p and prodict/load_df.p as well. It appears to have wrappers, dmpSch.p and loadSch.p. I haven't tried running PCT yet myself, but I don't see any optimizations in there that would improve the performance of creating a full/empty database schema. The task that I was investigating is called PCTCreateBase ... https://github.com/Riverside-Software/pct/wiki/PCTCreateBase
The only optimization I can think of is to attempt to manage *incremental* schema DF's, and use that for automated builds, but that seems like it adds extra complexity. I'd rather just send the full database DF as the input for our automated builds.
Another idea I had is to create some additional service that periodically checks for OE schema changes and extracts/creates the corresponding empty database with the same schema whenever a change is detected. That way a database is already prepared and ready to go whenever a new build is started. This seems a bit overly complex as well.
Yet another idea is to create multiple empty databases and split the schema arbitrarily across them. Then we could compile code that connects to these multiple databases. I think the resulting r-code would be the same as if it was all in a single database. I haven't tried this myself.
The reason we create an empty database is because we need the OE database to be local while compiling or else the runtime environment does a lot more work to pull schema over the network on the fly.
Any ideas would be appreciated.
A proserve isn't necessarily the answer. I tried various combinations and permutations of Type I, Type II, online, offline, different block sizes, etc. Some of them made less difference than I expected, maybe because the process is CPU-bound and there's a limit to what my single-hamster-driven machine will do.
You're using 4 KB block size. You didn't mention the contents of SimpleStructure.st. Are all the objects put into the schema area? Or are they put in application areas? Type I or II? *In theory*, using Type II will do more I/O as each object occupies a minimum of one cluster (8 or 64 or 512 blocks), even if empty.
As an example, when I load my schema into the schema area of an empty 4 KB database, the area grows from 2 MB to 10 MB. But when I have the tables and indexes assigned to Type II areas with 8 BPC, I get a 6 MB schema area, and areas 7 and 8 are 17 and 30 MB respectively. There is more I/O to do. That alone was good for about a 6.5 second difference (Type I being faster).
So try loading a .df with no area assignments; if your schema has them already, grep them out to create a new .df and load that. Add -r on your command line. Move your truncate bi before the load; try specifying -biblocksize 16 -bi 16384. See what difference those changes make for you.
How slow is slow?
Since it is a new, empty database with no user data and you can therefore just throw it away and try again if an unexpected problem occurs go ahead and use the -r startup parameter. -r provides almost all of the same performance benefits as -i but gives somewhat more in the way of recovery options.
Do NOT use -r or -i with any database that you are not prepared to throw away if something goes wrong.
You might also want to ensure that you have adjusted the bi cluster size prior to loading the .df.
Would it be an option to check for the CRC / timestamp of the database and then decide whether or not to rebuild it? You could do this in a starter .p (check DataDigger source for an example if you need one). You probably don't have db changes on each build so when you don't have db changes, this might save you the time of rebuilding the db.
Hi dbeavon
Our automated build street simply restores a backup of a database that's up to a certain point. We incrementally load df-files on top.
Fast and easy
How slow is slow?
Since it is a new, empty database with no user data and you can therefore just throw it away and try again if an unexpected problem occurs go ahead and use the -r startup parameter. -r provides almost all of the same performance benefits as -i but gives somewhat more in the way of recovery options.
Do NOT use -r or -i with any database that you are not prepared to throw away if something goes wrong.
You might also want to ensure that you have adjusted the bi cluster size prior to loading the .df.
> How slow is slow?
That's the question. I just did a bit of quick testing with the load of an application .df into an empty DB (552 tables, 994 indexes, 8820 fields, 11 sequences). First tests took about 36 to 40 seconds; tuning got it to about 14.
As Tom says, look at -r, BI tuning; also, try different block sizes and blocks per cluster.
@Tom
>> How slow is slow?
Good question. The database has about 1200 tables, 19000 fields, 200 sequences. It takes about 60 seconds to build the empty database for those tables. It is not terrible but it seems slow when you are waiting for the build to finish. It is also unfortunate when I see that the creation of the empty database takes more time than the compiling of the ABL code.
Also, my build server has eight cores running at 3.2 GHz, but a single CPU core appears to be the only resource that determines the duration of the operation . It seems like there is an improvement to be made here. I was hoping I would find some secret trick in PCT that would improve on the performance but I didn't see anything yet.
When I'm loading the DF schema, I current don't actually proserve the database. The program creates a connection in single user mode (-1). Similarly, while compiling ABL I can also do that from multiple processes without proserving as well, as long as we use the -RO connection option for the connected clients which are doing the compiling.
>> You might also want to ensure that you have adjusted the bi cluster size prior to loading the .df.
I'll try to do more digging on this topic. When I create the database it is with a pretty basic structure. And I never proserve. The overall process goes something like this (prior to starting the compiles):
At no point do I serve the database. The third step is where all the time is spent.
@Rob
>> .. tuning got it to about 14.
I'm amazed that you were able to tune the loading of the DF schema, and get it down to a fraction of the original time. I didn't realize there were that many dials and switches to work with. Can you provide all the commands and parameters that you used for doing that? It sounds like you guys are saying things would go faster if I did proserve the database? I had been assuming that would simply add extra overhead, and that the "-1" (single user) mode would be able to do the exact same work without any IPC between client and server.
I will try proserve'ing the database tomorrow and see if that makes the schema load faster than "-1".
Thanks for the tips.
Patrick and onnodehaan, thanks for the tips. I'm using _DbStatus-CacheStamp from the _dbStatus VST to see if the database schema has changed from the last time we ran a build. If there were no changes then I short-circuit the rebuilding of the empty database schema. This helps in some cases, but I only use that optimization for pre-production build operations. When compiling production code, then I unconditionally rebuild the empty schema no matter what.
A proserve isn't necessarily the answer. I tried various combinations and permutations of Type I, Type II, online, offline, different block sizes, etc. Some of them made less difference than I expected, maybe because the process is CPU-bound and there's a limit to what my single-hamster-driven machine will do.
You're using 4 KB block size. You didn't mention the contents of SimpleStructure.st. Are all the objects put into the schema area? Or are they put in application areas? Type I or II? *In theory*, using Type II will do more I/O as each object occupies a minimum of one cluster (8 or 64 or 512 blocks), even if empty.
As an example, when I load my schema into the schema area of an empty 4 KB database, the area grows from 2 MB to 10 MB. But when I have the tables and indexes assigned to Type II areas with 8 BPC, I get a 6 MB schema area, and areas 7 and 8 are 17 and 30 MB respectively. There is more I/O to do. That alone was good for about a 6.5 second difference (Type I being faster).
So try loading a .df with no area assignments; if your schema has them already, grep them out to create a new .df and load that. Add -r on your command line. Move your truncate bi before the load; try specifying -biblocksize 16 -bi 16384. See what difference those changes make for you.
Tried one more test: I put the db in tmpfs (in-memory file system). It doesn't make much difference; sometimes a second, sometimes less. The process appears to run at 100% of one core for the duration. So if you want to build the whole thing from scratch each time with a full .df, it appears the limiting factor is your core speed.
The tips about -r and -i were helpful. It appears that when I add those to my single-user load program (along with -1) then the DF load time consistently drops from ~60 seconds down to about ~53 seconds. That's seven seconds less time that I will have to twiddle my thumbs!
As far as my SimpleStructure.st goes, it is a simplification of what we have in production. It is just enough to load the actual DF's from production into an empty database:
# b BuildSchema.b1 # d "Schema Area":6 BuildSchema.d1 # d "abc1_log":7 BuildSchema_7.d1 # d "abc1_log_idx":8 BuildSchema_8.d1 # d "abc2_gl":9 BuildSchema_9.d1 # d "abc2_gl_idx":10 BuildSchema_10.d1 # d "abc2_je":11 BuildSchema_11.d1 # d "abc2_je_idx":12 BuildSchema_12.d1 # d "abc2_jehdr":13 BuildSchema_13.d1 # d "abc2_jehdr_idx":14 BuildSchema_14.d1 ...
These are Type I by default I believe. The actual structure from production looks more like so:
# d "Schema Area":6,64;1 /dbdev/develop/lum/lum.d1 f 1000000 d "Schema Area":6,64;1 /dbdev/develop/lum/lum.d2 # d "abc2_gl":9,64;64 /dbdev2/develop/lum/lum_9.d1 f 1000000 d "abc2_gl":9,64;64 /dbdev2/develop/lum/lum_9.d2 f 500
...
I don't know what the block size would be. It would be the windows default, I suppose. I think it was 4KB, not 8KB like in HP-UX.
>>the process is CPU-bound and there's a limit to what my single-hamster-driven machine will do
But what if you could get four or eight hamsters running at once? That is what I'm really going for. I'm wondering if I can arbitrarily chop up the DF and create a number of databases to compile against, rather than just one. Or maybe before compiling there could be a way to merge the areas created in multiple databases, so that they are combined into a single database?
The real problem is that load_df.p is written in single-threaded ABL. Maybe Progress should rewrite the dump_df/load_df in a multi-threaded way (or maybe they divide up the work and kick off some baby-batch.p to load it concurrently). That way more of my CPU cores will actually get put to use!
Speaking of I/O, I'd suggest testing with an .st file with fixed extents.
I've been testing something similar with type 2 areas and the I/O overhead to grow the variable extents was enough to be a real bottleneck.
Setting up the .st file to use fixed extents shaved a few seconds off of loading the .df. (With potentially much bigger gains to be had if you also need to load actual data.)
For type 1 areas the difference isn't going to be as big (for all the reasons Rob already pointed out above), but I'd still expect to see some gain.
I wouldn't suggest splitting into separate DBs, I believe that might affect your r-code functionally. Part of the metadata baked into the r-code is the logical db name(s). If you compiled your program against DBs A,B,C,D, and E, then deployed it to run against DB A, I'm not sure if that would work. You could test that easily enough.
So how fast is fast enough?
If you were to compile with DB connections A, B, C, D and E and then run with A connected and Aliasses B, C, D and E created for A (documentation.progress.com/.../index.html ) I think it would work. If it's really a desirable solution is another thing.
Rather than create fixed size extents... after having loaded your .df file the first time:
procopy $DLC/empty dbname
probkup dbname dbname.pbk
(at this point you will want to re-load the .df file if you plan to use this first iteration of the new db...)
Then, in the future, restore dbname.pbk on top of the previous iteration of your db rather than creating a new empty database. This will preserve the storage areas and the extent allocations while keeping everything variable length. If your existing process is creating storage areas with prostrct etc this will also allow you to skip those steps.
You would only need a new probkup if you add storage areas or if you add enough tables and indexes that the expansion of the areas starts to be noticeable again.
>> So how fast is fast enough?
Maybe 1/10 or 1/5 what it is now. Or at least 1/#CPU available. I guess I don't like any CPU bottleneck that seems somewhat artificial (where the operation takes 50 seconds because it is only aware of one of my cores out of 8).
It doesn't seem like there is any technical reason why the schema tables should be created one at a time rather than concurrently. Ideally some of the work could be done concurrently, off to one side, and then synchronized at the very end and merged into the final results. Even if we allow that the work must be done entirely on one core, then I still find it fairly odd that this takes 50 seconds on a 3.2 GHz CPU. I can't imagine what type of validation work it must be doing to take that long! I'm guessing much of the work is unnecessary and could be totally by-passed in the specific scenario that I'm describing (ie. because the database is new, is empty, and is not even served). I'm guessing that much of the work might involve checking for database users, schema locks, pre-existing schema, and pre-existing data.
We have a fairly large project with ~25,000 compiles (.p and .cls) and ~50,000 source files. And the compiling of the source takes only about 30 seconds on eight cores. So it is unfortunate when the initial creation of an *empty* database takes almost *twice* that time.
Hi dbeavon
Just a sidestep, but how do you compile that fast? In our automated build street we compile every single file with a seperate command, which is rather slow.
The collegeau's who build it, said that that's the only way you can build, but it sounds like you are using a faster way?
About the cores. It's just an 4GL program which loads the schema. We all know that A. 4GL is not particularly fast and B. it always on a single core since the AVM is not MT. 1200 tables in 60s is not that bad.
@onnodehaan
For anything CPU-bound you should always be able to scale-up the workload on a big server with multiple CPU's. The first thing to do is just open the task manager while that "build street" is running and see if the CPU is fully utilized (all cores simultaneously). If not then there may be something fishy going on.
In your case, the limiting factor might be some third-party dependencies that your colleages might not be able to control (eg PCT or similar). There may be limitations in these third-party dependencies that limit the utilization of CPU (similar to the limitation of OE when it is creating an empty schema).
Otherwise the steps for OE alone should be something like so:
Here is an example of a compile program that would build and save all 1000 source programs in a batch.
SESSION:SUPPRESS-WARNINGS-LIST = "15090". PROPATH = "Whatever". MESSAGE "...compiling... cyc\p\cyc0001.p". COMPILE cyc\p\cyc0001.p GENERATE-MD5 SAVE. MESSAGE "...compiling... cyc\p\cyc0002.p". COMPILE cyc\p\cyc0002.p GENERATE-MD5 SAVE. MESSAGE "...compiling... cyc\p\cyc0003.p". COMPILE cyc\p\cyc0003.p GENERATE-MD5 SAVE. ...
If there are no unusual third-party dependencies, then you should be able to double-check your colleage's findings. Something good will probably come out of it. There is always room for improvement. If you spend some of your day waiting on builds to finish, then there is ROI in improving the build process. Even the saving of 10 seconds can add up ... if you do builds for four staging environments, with five databases in each environment (which need their own r-code because of schema drift) and multiple iterations of this is required on a given day (a bad bug-day).
Below is what the task manager looks like during compiles (eight cores with full utilization). Make sure that disk isn't ever the bottleneck by using SSD. Also, make sure you have plenty of RAM because the file system cache is even faster than the SSD.
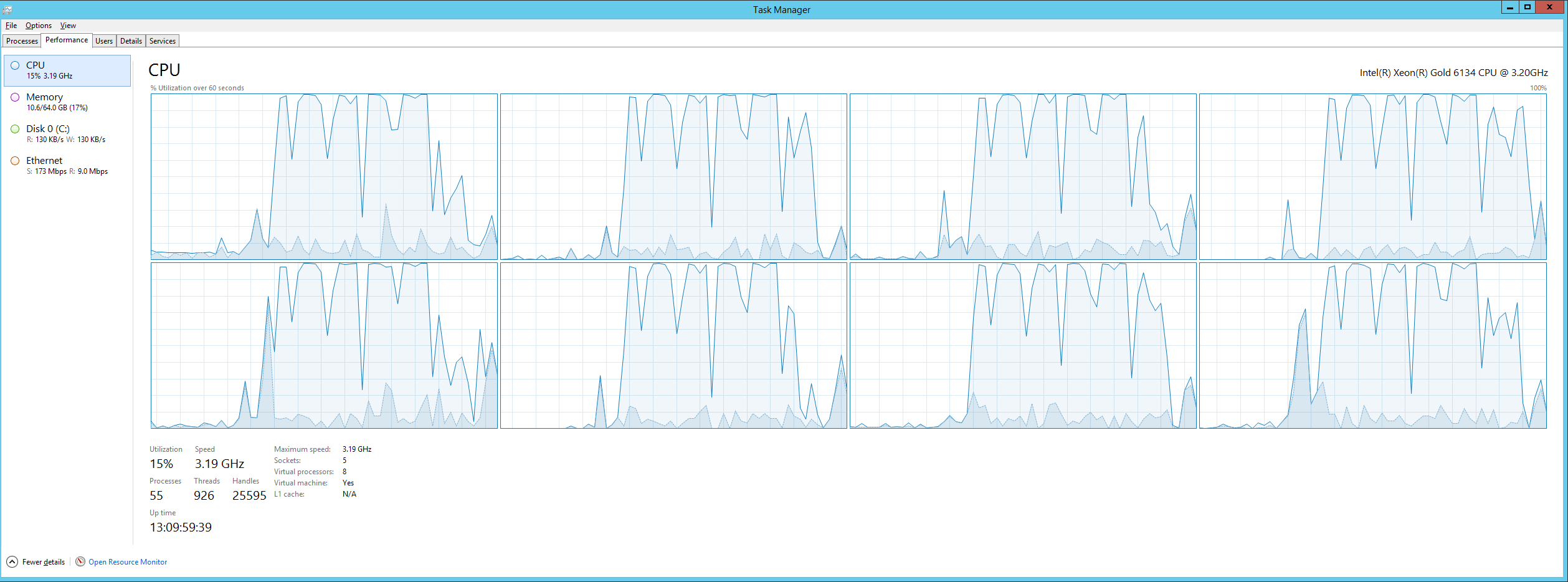
If you are the one that has to wait on builds, It is important that you have some control over improving them. If someone else is managing your builds for you, then you will have the troublesome task of trying to convince them why 50 seconds is better than 60 seconds. (Although they would probably understand if it was their own time that was being wasted ;) Good luck.
> On Dec 6, 2018, at 10:33 AM, dbeavon wrote:
>
> It doesn't seem like there is any technical reason why the schema tables should be created one at a time rather than concurrently.
nor has it been thought to be important to optimize this process. also, if you are making schema changes so frequently that it interferes with your build process, maybe you should spend more time thinking and less time making schema changes.
>> nor has it been thought to be important to optimize this process
Clearly.
Waiting an software builds is a real-world problem. It is probably the least enjoyable aspect of software development. And because OE source code has such tight dependencies on OE schema, then it is difficult to tear apart these two concerns. I should also say that the act of getting the empty schema, and making a *local* copy on a build server is NOT actually my first choice. But it is necessary, since ABL compiles itself so inefficiently against a *remote* schema. (I suppose the performance of compiling ABL code isn't thought to be important by Progress either.... PDSOE takes over an hour to compile our ABL project, the last time I dared to test it.)
I think my current plan is to wait for Progress to formally adopt (& support) PCT and then start submitting all my build-related support issues thru that channel.
A best-practice build process is to have everything that is required to build the artifacts inside source control, or build-able from items inside of source control. Relying on a fresh database is the best-practice approach. In a world where there could be multiple builds all running concurrently on the same build slave, all potentially requiring a different schema definitions, the only way to do it is to recreate the database each time.
The database needs to be treated like code, versioned and reproducible from the repository. I don't think a solution that relies on something outside of source control is a workable solution.
[quote user="dbeavon"]
I think my current plan is to wait for Progress to formally adopt (& support) PCT and then start submitting all my build-related support issues thru that channel.
PCT IS part of 11.7.4. It was released end of October and is formally included in the download.
[mention:f0668804e0e740dd872f501c6ac7df92:e9ed411860ed4f2ba0265705b8793d05] are very good at offering pro bono support for it too.
> making a *local* copy on a build server is NOT actually my first choice.
> But it is necessary, since ABL compiles itself so inefficiently against a *remote* schema.
In that case, maybe all you need is a local schema cache?
@ske
That is a very good thought, and I have made some attempts in the past to leverage schema caching for these types of things.
But schema cache doesn't work well (or at least not consistently well) from my experience. There must be a lot of special-case rules in the AVM about when/where it is allowed to use the schema cache. Even "DYNAMIC QUERIES" will ignore the schema cache at run-time, and that seems to be the scenario where the cache is intended to have its greatest effect. It has been a while but I think I had tried improving the performance of PDSOE compiles by using schema caching and wasn't very successful. I suspect that ABL compile operations don't use the cache in general. Perhaps it is only used by the AVM's runtime validation, whereby comparisons are made between the r-code and the database structure.
The docs say that the cache is a "complete schema or subschema for a single OpenEdge database", but I don't know if it is used as the "authoritative" schema, or as a perfect substitute for accessing the database directly.
@James
I had seen that PCT started being installed as part of OE. But Progress didn't seem to be ready to offer direct support. I would be happy talk to Riverside about the performance problems in the context of schema operations, but I suspect they would redirect me back to Progress. I think I'll have more luck once there is a single point of contact that takes responsibility for the whole process (the build performance, along with the related schema operations)
@danielb
I think you are making the same case I am. If we want our automated builds to use inputs that consist of both code *and* schema from source control, then we will often be creating fresh OE databases from the related schema. Optimizing the creation of fresh OE databases is key to having good build performance.
My point earlier was that if I compile against local schema, there is a price to pay; but if I compile 25,000 programs against remote schema there is an even higher price to pay.
Ideally I'll find a way to optimize the creation of the local schema. Perhaps we'll need to start using our source-control tools (or nuget package control?) to check-in the schema along with a full zip of the corresponding OE database. Then the only CPU is cost at the time of build is the unzipping of the OE database. Its a bit ugly, but our build operations would be faster.
We have a compressed, empty database. When needed, we erase the current database and decomp the ZIP. Very quick.