
Hi,
I want to bring something to the attention of the community as I think this is valuable information.
When a query/for each is using a non-unique index to iterate records, Progress ensures a consistent sorting of the records with identical index values.
It seems like the ROWID of the record is silently appended as extra segment of the index in that case.
E.g. If you do FOR EACH Customer BY SalesRep, all Customers having the same SalesRep will always be displayed in the same order, and not mixed in each run of the query. Also, when reversing the BY clause, they are still consistently sorted in reverse order.
While this looks like a sound solution, we have a case where this causes very strange, yet perfectly explainable, behavior.
Problems can be seen when creating a temp-table having a non-unique index, e.g by creating it LIKE a db table (inheriting structure and indexes from the db table).
In that case the order in which the records are created in the temp-table influences the way they will get iterated when performing a query using the non-unique index.
To demonstrate this, I've written a small procedure using the sports2000 db to demonstrate this.
The procedure will get the LAST 50 records by using a DESCENDING sort order. This DESCENDING sort however is the trigger to the strange behaviour...
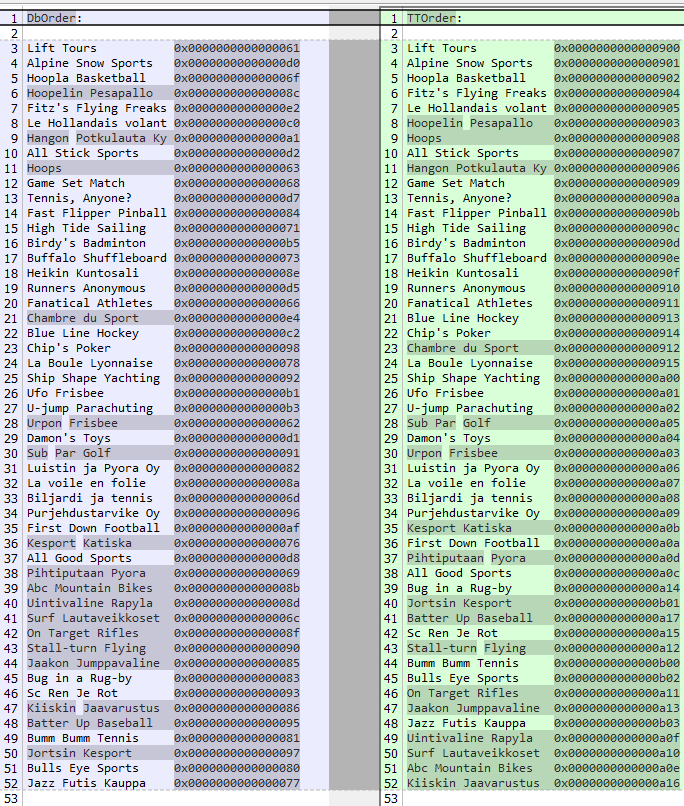
In the resulting output you see several records switched places, even though the same data, BY clause and indexes are used on both the temp-table and the db table.
DEFINE VARIABLE Counter AS INTEGER NO-UNDO.
DEFINE VARIABLE DbOrder AS CHARACTER NO-UNDO INITIAL "DbOrder:~n".
DEFINE VARIABLE TTOrder AS CHARACTER NO-UNDO INITIAL "TTOrder:~n".
DEFINE TEMP-TABLE tt_Customer LIKE Customer.
DEFINE QUERY CustomerQuery FOR Customer.
/* --------------------------------------------------------------------- */
OPEN QUERY CustomerQuery FOR EACH Customer NO-LOCK BY Customer.Comments DESCENDING.
DO WHILE TRUE:
GET NEXT CustomerQuery.
IF QUERY-OFF-END("CustomerQuery") OR Counter = 50
THEN LEAVE.
CREATE tt_Customer.
BUFFER-COPY Customer TO tt_Customer.
ASSIGN
Counter = Counter + 1
DbOrder = DbOrder + "~n":U + STRING(Customer.Name, "X(20)") + " " + STRING(ROWID(Customer)).
END.
FOR EACH tt_Customer BY tt_Customer.Comments DESCENDING:
ASSIGN TTOrder = TTOrder + "~n":U + STRING(tt_Customer.Name, "X(20)") + " " + STRING(ROWID(tt_Customer)).
END.
OUTPUT TO "C:\Temp\DbOrder.txt".
PUT UNFORMATTED DbOrder.
OUTPUT CLOSE.
OUTPUT TO "C:\Temp\TTOrder.txt".
PUT UNFORMATTED TTOrder.
OUTPUT CLOSE.
MESSAGE "Output in C:\Temp\DbOrder.txt and C:\Temp\TTOrder.txt"
VIEW-AS ALERT-BOX.
Yikes!
To work around this my suggestion is to add a Rowid field to the temp-table and have it contain the rowid value of the db record. This Rowid field should be added as last segment in the non-unique index of the temp-table, making it unique and resulting in the expected order (i.e. the same order as the fields in the db).
Btw, this problem also manifests with unique indexes containing null values...
Sorting by key and then by rowid is a natural way to sort the index keys. It also improves an index compession. That is why the "default" index is always the most compact.
I don't see the problem - if the requirement is to have identical sort orders in all cases - even past the index field specification - then the sort needs to be more accurately specified.
The problem is for someone of us could be obvious both results are the same.
Thanks for the attention call Lieven!
> To work around this my suggestion is to add a Rowid field to the temp-table and have it contain the rowid value of the db record.
It will not work for databases with table partitioning. Application should not rely on db internals - the internals can be changed in future. Each table in database should have an unique index - this area is under total control of the application's developers.
We are (currently) not using table partitioning, so for us this is not an issue...
The best solution would be to change all non-unique indexes and add the auto id field as last segment. This implies having such an auto id in the first place off course...
> The best solution would be to change all non-unique indexes and add the auto id field as last segment.
What is an aim? To provide the exact sorting order of table's records and their copies in temp-tables? It's very specific (and rare) task. Why to "lame" all indexes for it? Non-unique indexes are compact - less disk IO. Records with non-unique keys are retrieved in the order of their physical location inside database if these keys are sorted by rowid - less seek time. For example, time to scan the whole table may vary by a few times (or ever a few tens times) depending of an index that is used to scan. Non-unique indexes are the winners in most cases.
It's easy to add a temp-table's field with rowids of the original records to provide a sorting match.
> This implies having such an auto id in the first place off course...
Any index components after a field with the unique values are useless. If the order of index components does not matter for the queries then I'd recommend to use the fields with the less number of unique values as the leading components.
> It will not work for databases with table partitioning.
It will not work in *any* database where the DBA decides to run a tablemove while your code is executing, and now the ROWIDs are all different.
Heed George's words: developers should not rely on ROWIDs.
Hi George,
Let me quickly try to explain how I encountered this problem, to give an insight.
We have a grid that can show the data of a temp-table. The data comes from a db table with the same structure (fields and indexes) as the temp-table.
The user is allowed to press the END key, after which we retrieve the LAST batch of n records from the db and populate the temp-table with (only) those records. When the user scrolls UP, the moment the first record gets becomes visible, the server is requested for the next batch of records (which is logically the previous batch, as the user is scrolling up).
When a non-unique index is used, this scenario causes problems.
In that case, because the ROWIDs of the records matters for the sorting of duplicate index values, the next batch retrieved from the server will get sorted AFTER the records already on the client, instead of BEFORE, since their ROWIDs are higher (newly created records on the client), whereas they were lower/before on the server...
To clarify what I just said, there are acceptable uses for ROWIDs. For example if you have a record in a buffer and you want to soon thereafter fetch that record into a second named buffer for that table, then you can FIND btable WHERE ROWID( btable ) = v-rowid. That's fine, it's a short-term use. But storing a ROWID for any length of time and depending on it to be consistent is risky.
Hi Rob,
Since Progress is adding ROWID silently to the equation, there is no other option but to add the auto id to the index in that case, otherwise you can never get consistent or reliable results.
I don't care about the specific sorting of "duplicate" entries (according to the non-unique index), I just want a consistent sorting between sessions/calls. If the ROWID is unfit for that than the index needs to be made unique...