
Hi,
We have a discussion going on here.
While it is clearly documented that grouping assignments into a single ASSIGN statement is useful for database field assignments, I can't find a definitive answer for simple variable/temp-table field assignments.
While we have a coding convention here to always use the ASSIGN keyword and group assignments, some people start to diverge from this, thinking it's obsolete...
What's the definitive answer on that?
i was told many moons ago for "undo" variables, each assignment makes a separate write to local-bi file for undo-ability.
so if you...
assign x = x + 1.
assign y = y + 1.
assign z = z + 1.
you write three times to lbi. however...
assign
x = x + 1
y = y + 1
z = z + 1.
would only write once to lbi.
when it writes to the lbi it writes all the undo-able stuff on each change so if you have a lot of vars/field it could mount up.
these days where most stuff is declared no-undo and machines are alot faster it may not matter so much.
i still tend to group them though.
OK, that's a good reason.
I'll adjust my question: is there any use for NO-UNDO variables, as those are most commonly used.
There has been a long-standing belief that using ASSIGN improves performance. I thought that was debunked, but I just tried this little experiment (on Windows) and it is consistently faster with the ASSIGN with or without NO-UNDO.
DEFINE VAR i1 AS INT.
DEFINE VAR i2 AS INT.
DEFINE VAR i3 AS INT.
DEFINE VAR i4 AS INT.
DEFINE VAR i5 AS INT.
DEFINE VAR i6 AS INT.
DEFINE VAR i7 AS INT.
DEFINE VAR i8 AS INT.
DEFINE VAR i9 AS INT.
DEFINE VAR ix AS INT.
DEFINE VAR etim AS INT.
ETIME(TRUE).
DO ix = 1 TO 5000000:
ASSIGN
i1 = 1
i2 = 2
i3 = 3
i4 = 4
i5 = 5
i6 = 6
i7 = 7
i8 = 8
i9 = 9.
END.
etim = ETIME(FALSE).
MESSAGE etim VIEW-AS ALERT-BOX INFO BUTTONS OK.
ETIME(TRUE).
DO ix = 1 TO 5000000:
i1 = 1.
i2 = 2.
i3 = 3.
i4 = 4.
i5 = 5.
i6 = 6.
i7 = 7.
i8 = 8.
i9 = 9.
END.
etim = ETIME(FALSE).
MESSAGE etim VIEW-AS ALERT-BOX INFO BUTTONS OK.
[quote user="Laura Stern"] There has been a long-standing belief that using ASSIGN improves performance. I thought that was debunked, but I just tried this little experiment (on Windows) and it is consistently faster with the ASSIGN with or without NO-UNDO. [/quote]
As I recall from the docs, ASSIGN does all the assigns as a single instruction, while individual "=" do them separately - hence the slight bump in performance.
The rare times you'd want break up an ASSIGN is to when some of the fields are part of an index and you need to ensure that an index constraint isn't violated.
The rare times you'd want break up an ASSIGN is to when some of the fields are part of an index and you need to ensure that an index constraint isn't violated.
Way back in the v6 days using ASSIGN instead of single statements definitely had a performance impact AND created smaller .r code (back when you had a 64k .r code limit). I still group them together with ASSIGN because I think it's easier to read - unless there's a case such as Peter suggested.
> On Jan 14, 2016, at 11:59 AM, Peter Judge wrote:
>
> The rare times you'd want break up an ASSIGN is to when some of the fields are part of an index and you need to ensure that an index constraint isn't violated.
well ... don't do that.
if you do that, you make 1 database operation (i.e. a create) into a create followed by one or more updates.
this will happen because index entries contain the rowid of the record. since a rowid is an encoding of the storage location assigned to record (or the first fragment thereof) the rowid cannot be determiend without first creating the record.
i once worked with a customer that had /half/ of their database workload on a big single table and its indexes. for every record created in that table, there was a create followed by an update. when they fixed that, the volume of bi and ai data was reduced by roughly one fourth and the overall database workload was greatly lessened as well.
performance was much better after.
I wrote "the rare times" - this shouldn't be a normal practice unless a report comes in from the field or from testing that there's a problem with index violations and its traced to a single assign statement.
Personally, when I have the option I'll use temp-tables for intermediate work and then FOR EACH / BUFFER-COPY to update the db.
A good read, albeit dated, on the ABL ASSIGN: (https://blog.abevoelker.com/progress_openedge_abl_considered_harmful)
Look for the section titled "ABL: Un-optimized language compiler."
While the article is a bit negative , the point is valid. There is no reason we should be sitting around talking about whether its better to assign separate variables in one statement or two. These things are the job of a compiler and doesn't need to be a repeating concern for individual ABL programmers working on business as usual.
[quote user="Laura Stern"]
There has been a long-standing belief that using ASSIGN improves performance. I thought that was debunked, but I just tried this little experiment (on Windows) and it is consistently faster with the ASSIGN with or without NO-UNDO.
[/quote]
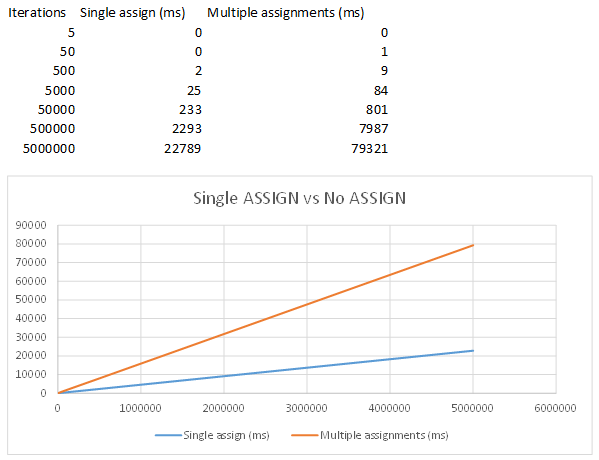
While the difference looks immense when using 5000000 iterations, the impact is negligible in everyday code.
I've plotted the results for 500000, 50000, 5000,... and get a pretty consistent linear relation between the times.
Using 5000 iterations or less, the difference should hardly be noticeable...
One thing to consider is error handling. Sample code:
DEF VAR d AS DATE.
DEF VAR i AS INT.
ASSIGN i = 1
d = DATE("x") /* assign is interrupted here */
i = 2 /* this is not executed */
NO-ERROR.
MESSAGE i. /* = 1 */
ASSIGN i = 1.
ASSIGN d = DATE("x") NO-ERROR.
ASSIGN i = 2.
MESSAGE i. /* = 2 */
The first message displays 1; the first assign is interrupted because of failing date conversion. The second message displays 2 because also the last assignment is executed. In this case the failing conversion is not disturbing other assignments. So this might have an influence on how you write assigns.
> The first message displays 1; the first assign is interrupted because of failing date conversion.
I think you have a valid point, but your example doesn't work as described. DATE("x") does't cause any error when I try it, it just returns the unknown value. DATE("1") works better for me.
Does anyone know what the reason is that this:
ETIME(TRUE).
DO ix = 1 TO 5000000:
i1 = 1.
i2 = 2.
i3 = 3.
i4 = 4.
i5 = 5.
i6 = 6.
i7 = 7.
i8 = 8.
i9 = 9.
END.
etim = ETIME(FALSE).
MESSAGE etim VIEW-AS ALERT-BOX INFO BUTTONS OK.
is slower then this:
ETIME(TRUE).
DO ix = 1 TO 5000000:
assign i1 = 1.
assign i2 = 2.
assign i3 = 3.
assign i4 = 4.
assign i5 = 5.
assign i6 = 6.
assign i7 = 7.
assign i8 = 8.
assign i9 = 9.
END.
etim = ETIME(FALSE).
MESSAGE etim VIEW-AS ALERT-BOX INFO BUTTONS OK.
Of course grouping the statements is the fastest way but one of our developers asked me why seperated assign-statements are faster then statements without the assign keyword and I really can't explain the difference. Does the compiler something different when he finds an assign keyword?
While there seems to be a small difference between multiple assignments with and without ASSIGN keyword, the difference is really marginal.
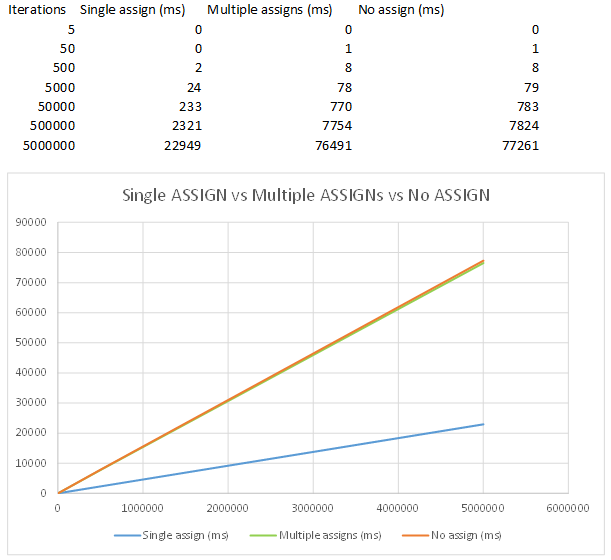
So my view on this is that there iso such thing as negligible performance loss.
Every ms counts in the real world and there is no excuse why the ABL compler should not optimize code like every other compiler in the world already does (and with good reason).
Some people here think that this doesn't make an impact on real world application performance and maybe they are right.
The Assign optimisation alone will not produce a huge impact.
But this is only one of many many things the compiler can and should optimize.
For everyone that shares my point of view, i create a new idea so people can vote for this.