
Hello Everyone!
So, we have problem on our PRODUCTION environment. If you know something about this article, please help us to resolve this problem.
One host (1xCPU Xeon E5-2683, 32 logical processors), two virtual machines. I just want to mention, that latest VMWare tools are installed, we don't use selinux iptables. No switches or firewall between these VMs!!! As I know, same problem is with latest Debian kernel.
- VMWare 6.5
- Centos 6.9 and Centos 7.7, clean, wihtout patches and software, we took Centos minimal installation.
VM1 (Centos 6.9)
- one processor
- RAM 2Gb
- SSD disk RAID10
VM2 (Centos 7.7)
- one processor
- RAM 2Gb
- SSD disk RAID10
Both OpenEdge 11.7.2 installed, this is release what we use on PRODUCTION environment.
So, lets start with a tests:
VM1 run iperf3 -s
VM2 run iperf3 -c "VM1.domain"
We have speed about 15Gb/s
another test
VM1 run iperf3 -c "VM2.domain"
VM2 run iperf3 -s
we have speed about 30Gb/s.
Also we tested speed from localhost to localhost on Centos6 and Centos7. Same result, Centos6 is about two times faster than Centos7.
--------------------------------------------
So same situation with Progress.
We have about performance degradation with FOR EACH from Centos 7 to Centos 6.
I want to also mention, that we have another DB vendors, no others shows any problems.
Data from Progress:
--------------------------------------------
DB Start script on both servers:
/usr/dlc/bin/proserve /xxx/xxx -n 65 -ServerType 4GL -S 2222 -Mpb 5 -Mn 9 -Mi 1 -Ma 7 -aiarcdir /xxx/xxx/xxx -aiarcinterval 3600 -aistall
/usr/dlc/bin/proserve /xxx/xxx-m3 -ServerType SQL -S 3333 -minport 3334 -maxport 3400 -Mpb 3 -Mi 1 -Ma 6
$DLC/bin/proapw /xxx/xxx
$DLC/bin/probiw /xxx/xxx
$DLC/bin/proaiw /xxx/xxx
--------------------------------------------
Startup.pf
-cpinternal KOI8-RL
-cpstream KOI8-RL
-cpcoll RUSLAT
-cpcase BASIC
-d dmy
-numsep 44
-numdec 46
-Mm 16384
-maxport 3000
--------------------------------------------
So, here are test results on different Centos servers.
Done with database sports2000
Centos 7
CONNECT command 1155ms
Run NO-LOCK NO-PREFETCH SHARE-LOCK 1 88 7137 26541 2 102 6281 26013 3 87 7259 25303 4 82 7381 25318 5 88 6883 27381 6 84 6472 27532 7 79 6101 25775 8 87 5960 27045 9 82 6029 25494 10 111 4909 26087 11 80 6284 26263 AVE 88.2 6426.9 26250.2
Centos 6
CONNECT 15ms
Run NO-LOCK NO-PREFETCH SHARE-LOCK 1 79 1353 1736 2 75 1364 1624 3 80 1368 2049 4 80 1328 1729 5 93 1508 1683 6 79 1368 2015 7 99 1550 1730 8 73 3714 1924 9 93 1643 1668 10 90 1426 1679 11 87 1392 1809 AVE 84.4 1637.6 1786.0
SCRIPT:
DEFINE TEMP-TABLE ttResult NO-UNDO
FIELD uRun AS INTEGER FORMAT ">9"
FIELD uTime AS INTEGER FORMAT ">>>>>>>>9"
FIELD uCount AS INTEGER FORMAT ">>>>>>>>>9"
INDEX i-run uRun.
DEFINE VARIABLE tTime AS INTEGER NO-UNDO.
DEFINE VARIABLE i AS INTEGER NO-UNDO.
DO i = 1 TO 11:
ETIME(TRUE).
FOR EACH OrderLine NO-LOCK /*NO-PREFETCH*/:
ACCUMULATE "rec":U (COUNT).
END.
tTime = ETIME.
CREATE ttResult.
ASSIGN ttResult.uRun = i
ttResult.uTime = tTime
ttResult.uCount = ACCUM COUNT ("rec":U).
END.
FOR EACH ttResult NO-LOCK:
DISPLAY ttResult.
END.
If you know something about this, please let me know!
If the OS sees the network as being twice as slow then I don't think you can blame Progress for that.
Other databases might be less sensitive to network speed if they are less "chatty" than the Progress client/server protocol. If you cannot get the OS level difference resolved and have to accommodate slower speeds then you might want to try increasing -Mm and using the various -prefetch* parameters rolled out with OE10.2B06. -prefetchNumRecs is the most influential. Using FIELDS lists along with a very large -prefetchNumRecs is quite helpful.
You're getting killed in the "no prefecth" and "share-lock" examples because those are not "no-lock queries" and each record is fetched individually which takes (at least) 3 network messages. So the impact of slower speeds is magnified.
Hello ChUIMonster.
We increased speed for network by changing parameters of the kernel.
iperf3 shows about 20-23Mb/s with tuned parameters, but it doesn't help for progress. Same results for connection and for transfering data.
I don't understand why connection and transfer of 2-3Mb of data is going about 3-5 seconds.
Also I didn't mention that this is progress progress problem, I just want to get information, maybe anyone get same problem and somehow resolved this.
Also speed 15Gb/s is quite good for any server for our environment, our progress DB is only 60Gigs. I can read whole database in less than 10 seconds. It is strange that it works like it works now.
Artur,
Do you agree that the issue is a round trip time (RTT) rather than network bandwidth in common?
SQL databases are much less affected by the issue because they operate with the set of data and they send data over network in large messages. Progress does the same with FOR EACH NO-LOCK queries and they are almost not affected by the issue as we can see from your Progress tests.
Connection (without the -cache) to Progress database is affected because a session reads the most of metaschema records with SHARE-LOCK which means one record per network message. In your case a connection with the -cache is 3 times faster. It reads 100 times less metaschema records and uses SHARE-LOCK only 3 times. I would expect that a connection with the -cache should be much faster.
In your Progress tests 'FOR EACH SHARE-LOCK' is much slower than 'FOR EACH NO-LOCK NO-PREFETCH'. SHARE-LOCK does add the overheads but it's only 9% on CentOS 6 (1786.0 vs. 1637.6) and 4 times on CentOS 7 (26250.2 vs 6426.9). When we use the queries with SHARE-LOCK a remote client server received twice more messages from its client than when we use NO-LOCK NO-PREFETCH (the additional messages are the requests to release the locks). The number of network messages sent by a server to a client is the same in both cases. I guess CentOS 7 has an asymmetrical issue with RTT. Round trip time seems to depend from a direction. Does iperf3 reuslts depend from where you run it? Can you repeat Progress tests while the location of client and sports2000 db is reversed?
Yes George, RTT is connected with bandwidth, it is not the same, but it really close to that.
Centos 7 HAS asymmetrical issue with RTT. Latest kernel is slow, as initiator but fast as receiver. Older kernel is fast in both ways.
I will try to repeat tests with reserved location, but I think it would have any advantage.
Some numbers for the tests with sports2000 db:
FOR EACH OrderLine NO-LOCK NO-PREFETCH /* SHARE-LOCK */: ACCUMULATE "rec":U (COUNT). END.
promon/Activity: Servers
NO-LOCK NO-PREFETCH SHARE-LOCK Incr Messages received 13979 27949 +13970 Messages sent 13976 13976 Bytes received 1509396 2124076 +614680 Bytes sent 2086135 2086135 Records received 0 0 Records sent 13970 13970 Queries received 13971 13971
The sizes of individual network messages:
Queries received: 108 bytes Release Lock: 44 bytes Records sent: 149 bytes (average rec size is 43 bytes) Bytes sent: 2,086,135 bytes Record size: 605,019 bytes (according to tabanalys)
SHARE-LOCK query is drastically slower on CentOS 7 because it uses the additional 13970 messages to release a lock. But the main difference, me think, is very small size of these messages.
I would run the similar tests against a table where I can control the size of the records. The aim is to check how the execution time of NO-LOCK NO-PREFETCH depends from record's sizes (from the network message sizes). It looks like the smaller network messages the slower the query.
When the OE database runs across a client/server connection you need to watch packets per second first, and CPU next (on both sides.) The performance of the app really is all about the latency of those packets, and the time it takes to turn them around (RTT). For any OE ABL program that is running slowly, I typically expect to see my packets per second hovering between 6,000 and 10,000. Unless the code is doing FOREACH-NOLOCK scans, then the payload of those individual packets is extremely small.
If you want to understand the performance characteristics of the protocol better, I highly recommend downloading wireshark and watching the I/O graph. If nothing else, it is somewhat cathartic and gives a way to pass the time as your queries are executing....
Below is the retrieval of ~1500 documents via client/server. Notice that it takes about 15 seconds and the packet exchange rate is over 10,0000 for the entire time.

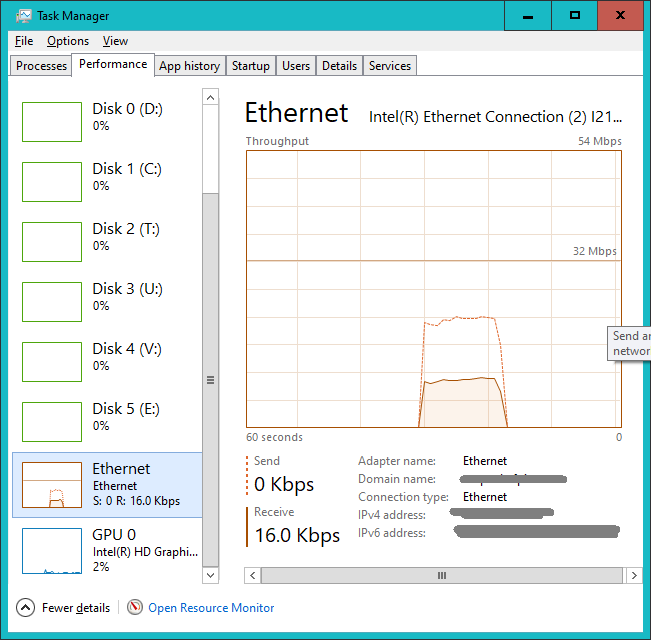
The first image is from wireshark and the second is from task manager. I think it is especially interesting that my "query" of these documents involves sending almost twice as much data to the database server as what I'm receiving. I'm not sure what the protocol is doing that requires so much data to be heading in the wrong direction... I'm curious to take a look but haven't had the chance.
One last thing about the RTT. If there is some small amount of CPU (even a dozen ms per record) that is being used on the client then this can make all the difference between a packet rate of 5,000 and 10,000 packets per second. That is why CPU needs to be monitored as well!
This is probably not helpful to a Linux customer. But one thing to point out is that the OE database does have an ODBC interface. So if you are running ABL on Windows with the CLR bridge, then there is a workaround that can be used (probably as a very last resort). You can generate real SQL queries against the OE database, send them out via a .Net ODBC adapter, and transform the results to ABL temp-tables via JSON. It's quite a lot of programming effort but, depending on how long users are waiting for their data, there is the potential for a real large ROI. By using this approach you can even take advantage of server-side joins without having to upgrade to OE 12.
That sounds like perhaps the server is consolidating or delaying packets in hopes of making a bigger packet.
This knowledgebase.progress.com/.../P1290 doesn't specifically address the issue but it might provide some ideas about what to look for in Centos.
> On Oct 22, 2019, at 9:52 AM, George Potemkin wrote:
>
> SHARE-LOCK query is drastically slower on CentOS 7 because it uses the additional 13970 messages to release a lock
There has been a regression. In earlier releases (don't know when this was broken), lock releases were piggybacked onto the request for the next record. thus there were no extra messages to release locks in the for each example given.
> On Oct 22, 2019, at 10:03 AM, ChUIMonster wrote:
>
> That sounds like perhaps the server is consolidating or delaying packets in hopes of making a bigger packet.
There is a socket option called TCP_NODELAY which turns off that optimization (which is useful for telnet connections). Maybe it isn't working on Centos. Long ago (in the progress version 5 days), it did not work on any of the west coast UNIX operating systems until they were patched by the os vendor.
Hello!
So we used parameter: net.ipv4.tcp_autocorking = 0. It really helped for us. So we got speed very simuilar to Centos 6 on Centos 7 latest version.
Does anyone tried this option for TCP stack?
Can it be used in production environment for openedge databases?
It sounds like you figured it out. I think the OE software would be agnostic about that. If they cared, then it seems like they could explicitly program for it (similar to introducing TCP_NODELAY as an option whenever opening a TCP connection). You could open a quick support ticket with tech support and they will write a KB article. It would be helpful for other customers who are upgrading their OS'es as well.
I think it is surprising that we don't find many google hits about tcp_autocorking in general.... I suspect OE is in an elite class of applications that are so chatty that this parameter would make a substantial impact.
Here is another that I found (monkey web server). It disables tcp_autocorking too:
Ubuntu would probably be affected by this too. Per their docs about TCP_CORK, it can introduce an artificial delay (of up to 200 ms!!! manpages.ubuntu.com/.../tcp.7.html )
" If set, don't send out partial frames. .... As currently implemented, there is a
200 millisecond ceiling on the time for which output is corked by TCP_CORK. If
this ceiling is reached, then queued data is automatically transmitted. ... "
If several Linux OS'es have started to enable autocorking by default then OE needs to get ahead of that right away ... or the database will appear even more slow than it needs to be. Perhaps it is one of the database improvements they have already made in OE 12. Ie. perhaps cork-management might account for some of the 300% improvement that they have been advertising!
0) The TCP_CORK socket option enables message aggregation for 200 msec for small messages. You do not want that. oe should not set that option.
1) the quite old tcp socket option TCP_NODELAY (which oe sets for database connections and should set for all other sockets) shuts off message aggregation. this is good for lots of communication protocols.
message aggregation is useful for applications (such as telnet) that send character at a time as a user is typing and local echo is on (or other teeny tiny packets). in that case. waiting for 200 msec allows for more characters to be typed and fewer packets to be sent.
3) tcp_autocorking tells the operating system to decide when to do message aggregation and for which sockets. depending on applications, it may help or make things worse.
4) since use of corking and autocorking is still somewhat rare, there could be unintended consequences (kernal bugs) in interactions amongst combinations of TCP_NODELAY, TCP_CORK and tcp_autocork.
5) enabling tcp_autocorking is worth trying.
@gus, the latest OS releases are now enabling autocorking by default (both centos and ubunto, from what I understand).
@arturikk said he needs to change the kernel default, and disable the autocorking. That could be done as a way to avoid the aggregation delays that are imposed on the client/server database protocol. This reverts the kernel behavior to the way things worked in the prior versions.
In addition to asking customers to use a workaround like this, it seems to me that OE should be proactive ... they should start programming around the modern corking behavior of these Linux OS'es. Customers should not have to get to this level of technical detail. If OE needs to uncork more frequently then all the other applications on a Linux server then it should be doing that explicitly... See www.kernel.org/.../ip-sysctl.txt
"Applications can still use TCP_CORK for optimal behaviors when they know how/when to uncork their sockets."
This topic hits home with us as well ... not that long ago on HPUX we were having substantial performance problems with classic appserver. I reported the problem to tech support and they kept telling me that it was not reproducible. It turns out that, after a number of days, we learned that they were only testing the repro on Linux and Windows machines which were programmed with TCP_NODELAY (ie. disabling nagle's algorithm). But the HPUX installation wasn't working the same way. This is one reason - among many - to avoid staying on the sinking ship called HPUX.
I agree that customers should not have to get to this level of technical detail.
But: the kernel should NOT override TCP_NODELAY, which apparently tcp_autocork does under some (unknown) circumstances. OE does not want to enable TCP_CORK at all. (my private opinion, since i am retired and no longer at psc).
Really this is kernel feature whitch disturbs normal OE work. So, it could be greate if OpenEgde could fix this issuie, because I think I am not alone on that problem, and if someone will want to test speed of that DB, they wouldn't know anything about AUTOCORK parameters, witch is enabled by default in most Linux distributions. Or need to be instruction during installation for linux, for best perfomance to disable AUTOCORK.
OpenEdge developers/product managers please think of that!!!
Thank you!
We solved this problem for this time