
Hello,
I'm trying to learn how to manage performance in an OpenEdge database. I've set up a monitoring system. And I decided to start with setting the -spin parameter.
With the database works from 1.7K to 3.2К users depending from time of day. On the database server we have 128 CPU. Several databases are running on the same server. Currently the value of -spin is set to 10000 for all databases. On the monitoring system I set following thresholds for Latch timeouts: less than 300 - Ok(Green zone); more that 300 and less than 500 - Warning (Yellow zone); more than 500 - Critical (Red zone). I've noticed that most databases have the Latch timeouts value in the green zone (less than 300).
But in one database, the values of Latch timeouts are almost always in the red zone. On average 809, max 1.5 K.
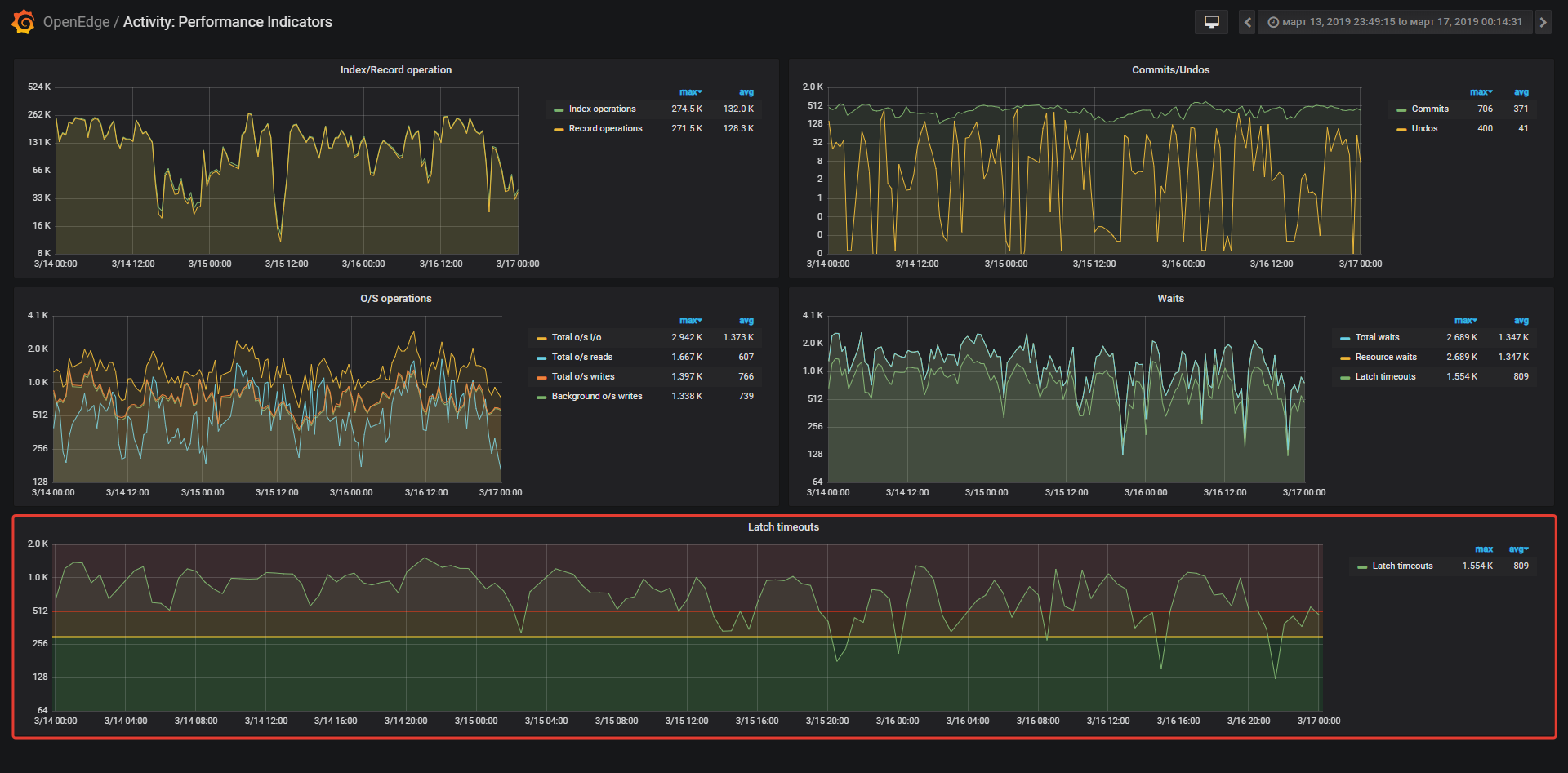
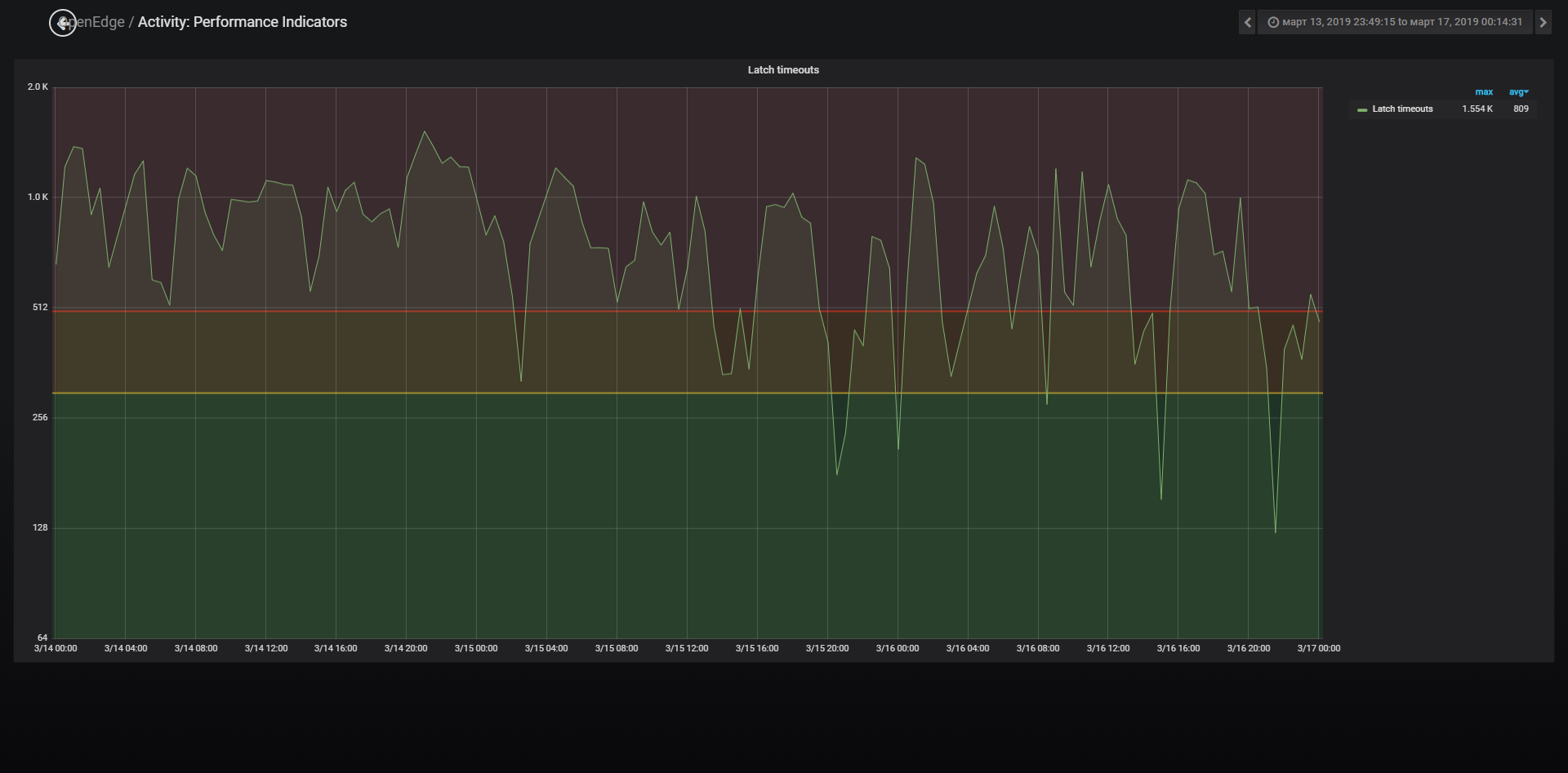
The question is, should I increase or decrease the -spin value for this database? Or maybe I should pay attention to some other metrics?
Thanks in advance for any tips!
>>On average 809, max 1.5 K.
That values is per second.
Latching is extremely sensitive to cpu affinity. 128 CPUs is a very, very bad thing for a database server. A server with 128 CPUs probably makes a great web server. It is not an appropriate database server.
Aside from that...
Noticing that you have possibly excessive latch timeouts is just the first step. You then need to know *which* latch is responsible. Your corrective actions will vary depending on whether the issue is excessive LRU waits or MTX waits. Or BHT waits. Or one of the BF latches. It can also depend on what version of OpenEdge you are running.
Once you know which latch is involved (hopefully just one will stick out) you might be able to "treat the symptoms" via -spin or -lruskips or something simple like that. On the other hand you might not. If it is MTX, for instance, then you probably have to do something like stop using RAID5 on a SAN for your bi file.
Ultimately you want to get to the problem behind the problem. In many cases this is going to be the behavior of 4gl code. For instance, a very frequent driver of excessive latch requests is 4gl code that is hammering on a small set of records. So you probably want to correlate latch requests with table and index activity at the detailed table and index level. And then you probably want to tie that back to particular user sessions if it is narrowly focused activity, or you want to find the frequently used bits of code that are responsible.
I should mention that ProTop does many of these things for you and would save you a lot of development time. And has nice pretty Grafana charts too. wss.com/.../
> But in one database, the values of Latch timeouts are almost always in the red zone
The cost of one timeout is unknown. Is it the -nap 10 or the -napmax 250 (or whatever is used by your customer)? The difference is huge. I'd change the -napmax to the -nap just to check how it will affect the latch timeouts. Significant increasing of timeouts would mean that a bottleneck on the latches is real.
Also I guess the -nap 1 would be a right thing to use.
> 128 CPUs is a very, very bad thing for a database server.
What is a percent of time when one Progress session uses the latches? 5%. Maybe 10% at most. So the most processes that are using CPUs right now are not locking the latches. The rest (~ 6 processes = 5% of 128 ) served by CPUs at the moment: only one process can lock a regular latch at time, a few processes can /try/ to lock the same latch. But if they failed then will sleep (nap 10 milliseconds) the thousands times longer than latch lock (~50-100 nanoseconds) leaving CPU time for the processes that don't need the latch locks.
And if a box is running many databases then the large number of CPUs will not be a bad thing at all.
I agree that just because you see what seems like a "high" value for latch timeouts that you do not necessarily have a problem. That is why you need to dig deeper and understand which latch or latches are involved.
I disagree that large numbers of CPUs is not an issue. Yes, you will get away with it if your load is not heavy. But there is a reason that certain platforms are so frequently mentioned when users are having performance problems.
To simplify a picture let’s assume that database has only one latch - MTX latch. The one I don’t like because when MTX latch is a bottleneck I don’t have any suggestions for the customers how to improve performance. Let’s assume a box has 128 CPUs. Will we get the stronger issue with Cache Coherency if we will split the whole table space, let’s say, in a hundred separate databases with their own copy of MTX latch?
It is an even bigger problem when too many cores are virtualized -- in that case enough free cpus need to be available before the hypervisor can schedule the VM. Which is what often causes the "my VM is painfully slow but it isn't doing *anything*" problem. Many times people add CPUs to the VM in an attempt to cure that problem. Which only makes it worse.
MTX is a bad example because the main improvement that you can make for that one is to address the IO subsystem. Well, the other main improvement would be to fix the code -- but it's usually a whole lot easier to fix the IO subsystem.
MTX lock duration is indeed affected by the IO subsystem but why? MTX latch can be locked during BI writes. But BIW does not seem to use MTX latch. Client's sessions do use MTX latch but in most cases they should not write to BI file.
For our biggest customers MTX latch has the highest timeouts among all latches.
I see a lot of situations where LRU and BHT are much bigger problems than MTX. And those cases are severely aggravated when the customer is on a NUMA box with dozens and dozen of cores. IMHO a handful of cores is plenty for almost every db server that we come across. A few fast cores is infinitely better than a horde of (slower) cores. (If you look at Intel's chip matrix you will also see that many cores also = slower cores.)
For update heavy applications, MTX is often a bottleneck. In this note writing work, the MTX is really used to order the recording of the bi and ai notes as an atomic action and not to protect each one individually.
Recording of OLTP actions grab MTX, then BIB, records bi notes and releases BIB, then grabs AIB and records ai notes, then releases AIB and MTX.
This is another reason why extending variable length bi or ai extents during OLTP operations can adversely affect performance.
The BIWs write full/dirty bi buffers and hold the BIB latch to protect new buffers being put on the full list by OLTP activity while the BIW is grabbing one off the list.
It would make sense to separate the latches used to record bi notes and management of the full bi buffer list. A BIB and BIW latch for example.
Same goes for the AIB latch but that mechanism is a bit different than the BI.
Currently, the ai and bi writers contend with the OLTP activity for the BIB and AIB latches and that is occurring while the OLTP action is holding the MTX.
The MTX would not be needed here if there were only one set of files to write notes to. In other words one recovery subsystem for BI and AI as opposed to two. The note recording latch and full buffer write latch would suffice. One set of notes, one set of files. It seems it would make sense to provide such an option. Of course DBA management of such a joined recovery subsystem would be a bit different than today based on archiving and long running txns as well as involvement in replication but should be consumable easy enough.
If such changes were ever made, it still would not remove the bottleneck of recording recovery notes since OE still maintains the write ahead logging rule database wide so managing OLTP updates will continue to be a bottleneck or have a funneling effect albeit with improved performance over today's implementation.
Tom, I hope you see significant improvements in BHT concurrency with those apps once they are deployed in OE 12.0.
-lruskips was certainly a big help! Hopefully -hashLatchFactor will be similarly beneficial :)
Hopefully not high jacking this thread...
-hashLatchFactor also was put into 11.7.4.
The other BHT performance enhancement only in OE 12.0 was the Optimistic Cursors feature. This will dramatically decrease the # of BHT latch requests for queries using cursors. Readprobe's: for each customer NO-LOCK: end. comes to mind ;)
Hopefully not high jacking this thread...
-hashLatchFactor also was put into 11.7.4.
The other BHT performance enhancement only in OE 12.0 was the Optimistic Cursors feature. This will dramatically decrease the # of BHT latch requests for queries using cursors. Readprobe's: for each customer NO-LOCK: end. comes to mind ;)
> On Apr 30, 2019, at 1:04 PM, George Potemkin wrote:
>
> MTX latch can be locked during BI writes
that is true but does not happen for every before-image log write. mtx latch is, as rich says, designed to coordinate storing before-image note in before-image log buffer, storing same before-image note in after-iamge buffer, and making the recorded change to a database block. those 3 operations must all occur in the same order (for a given database block, the transaction log notes and the block changes must happen in the same order).
note that writing to database, before-image log or after-image log is not required for those 3 things.
there are various optimizations that are possible to reduce concurrency and make these things happen faster but the required ordering /must/ be preserved for crash recovery, rollback, and replication to work.
Just run a quick “tranprobe” test. It’s Tom’s readprobe test but the readalot.p is replaced by:
DISABLE TRIGGERS FOR LOAD OF customer.
DEFINE VARIABLE i AS INTEGER NO-UNDO.
REPEAT TRANSACTION:
DO ON ERROR UNDO, LEAVE:
CREATE customer.
DELETE customer.
END.
END.
It’s the most aggressive transactions in Progress - no db writes, only 3 recovery notes per transaction.
The box:
NumCPU = 96
The sparcv9 processor operates at 1165 MHz (yes, it’s 10 times slower than the modern CPUs)
Result:
MTX locks reached approximately 200,000 locks per sec, 530 naps per sec at 15 users and ~ 230,000 locks per sec, 2,600 naps per sec at 100 users.
MTX latch was busy almost 100% of the time.
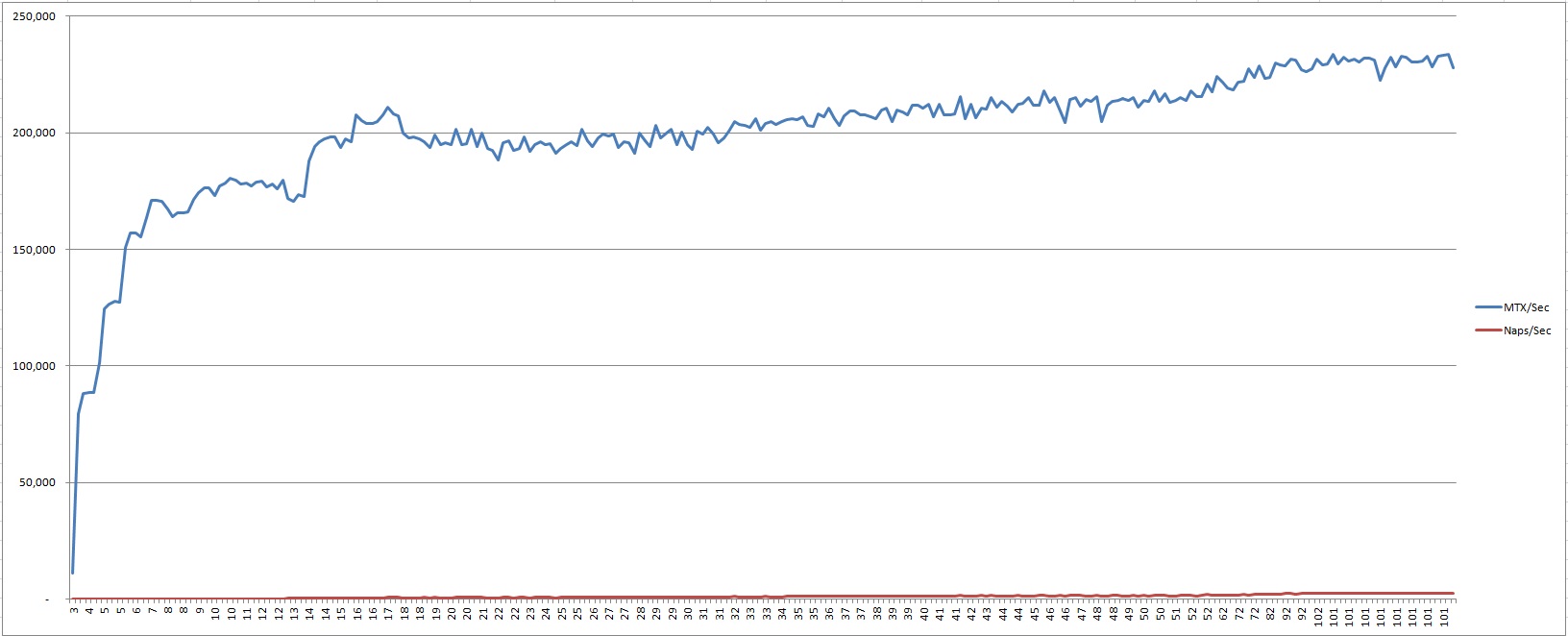
Only 70% of sessions opened the simultaneous transactions.
Transactions were in ACTIVE phase only 15-20% of the time, “Phase 2” – 50%, BEGIN – 33%, None -1.5-3%.
See MTX.xlsx
[View:/cfs-file/__key/communityserver-discussions-components-files/18/MTX.xlsx:320:240]
Forgot to mention: Commits were 50,000-58,000 per sec.
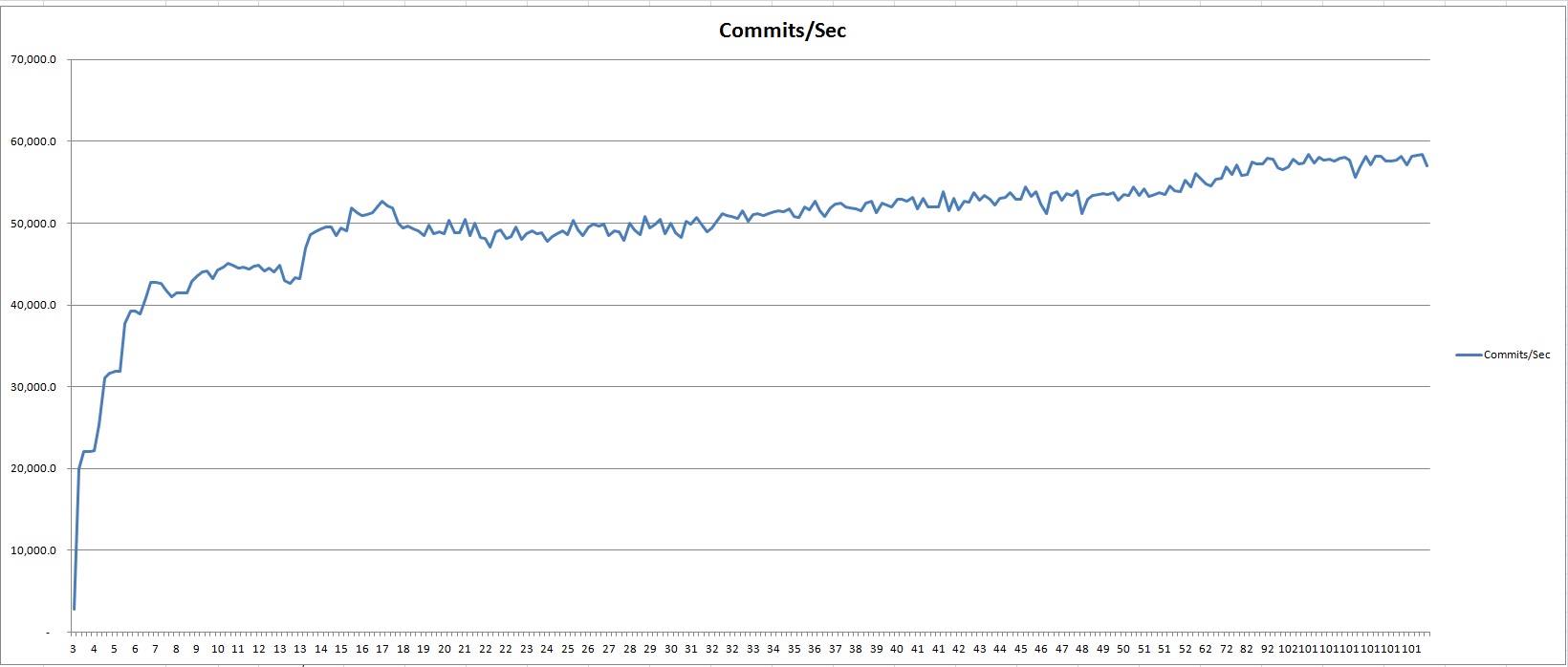
BI blocksize = 16K, BI cluster size = 256 MB, BIW was running,interval between checkpoints ~ 22-25 seconds, checkpoint durations ~ 25 milliseconds.
I think we can refer to that variation as "writeprobe" :)
Or bi note generator. ;-)
BTW, it has one feature that can be useful to test a replication: the notes will be totally ignored by replication agent - no DB/BI writes on target db. It's the fastest way to fill the pica queue.
> BI blocksize = 16K, BI cluster size = 256 MB, BIW was running,interval between checkpoints ~ 22-25 seconds
time proutil sports -C bigrow 1 -zextendSyncIO
OpenEdge Release 11.7.3 as of Fri Apr 27 17:00:27 EDT 2018 real 0m50.863s user 0m0.169s sys 0m5.429s
Both writeprobe and bigrow are only writing to BI file but writeprobe is twice faster.
BI consisted of 4 clusters before I run bigrow.
Really I run bigrow twice and the time was consistent.
It's a variable extent.
b ./sports.b1 f 2000128 b ./sports.b2
proutil sports -C truncate bi
time proutil sports -C bigrow 1 -zextendSyncIO
real 0m36.532s user 0m0.675s sys 0m12.588s
[2019/05/01@22:09:13.586+0300] P-27142 T-1 I DBUTIL : (451) Bigrow session begin for root on /dev/pts/1. [2019/05/01@22:09:13.586+0300] P-27142 T-1 I DBUTIL : (15321) Before Image Log Initialisation at block 0 offset 0. [2019/05/01@22:09:42.199+0300] P-27142 T-1 I DBUTIL : (7129) Usr 0 set name to root. [2019/05/01@22:09:42.199+0300] P-27142 T-1 I DBUTIL : (6600) Adding 1 clusters to the Before Image file. [2019/05/01@22:09:49.979+0300] P-27142 T-1 I DBUTIL : (15109) At Database close the number of live transactions is 0. [2019/05/01@22:09:49.979+0300] P-27142 T-1 I DBUTIL : (15743) Before Image Log Completion at Block 0 Offset 235. [2019/05/01@22:09:49.980+0300] P-27142 T-1 I DBUTIL : (334) Bigrow session end.
22:09:13.586 - 22:09:42.199 = 28.613 sec = 4 clusters (7.153 sec per cluster)
22:09:42.199 - 22:09:49.980 = 7.781 sec = 1 cluster
Writeprobe test creates the predictable latch activity that depends from Progress version:
11.6: (MTX + BIB) per recovery note + (MTX, 4*TXT, 2*TXQ) per transaction.
11.7: (MTX + BIB) per recovery note + (MTX, 4*TXT, 2*TXQ) per transaction.
12.0: (MTX + BIB) per recovery note + (MTX, 4*TXT, 2*TXQ, LKT) per transaction.
Update: if the sessions are started with -nosavepoint then we get nothing per recovery note and (2*MTX,3*TXT) per transaction i.e. +MTX and -TXT -all TXQs. The tests where the sessions are running with -nosavepoint should be called "latchprobe" tests - no DB/BI writes but only MTX/TXT latch activity. ;-)
Note that the code of writeprobe above creates only 3 recovery notes per transaction (RL_TBGN, RL_TMSAVE, RL_TEND) but the size of transaction can be increased by adding ‘i = 1 to 100’ to a sub-transaction’s block that will create an additional RL_TMSAVE note per loop.
Some of these latches are obviously locked when a process already holds MTX latch. Can somebody explain when these latches are locked individually and when they are locked under the cover of MTX latch? If first case we should get the contention for a particular latch. In second case we will have the contention only for MTX latch.
We can’t trust the “Owner” field in ‘Activity: Latch Counts‘ screen or in _Latch-Owner because the time to get this information for the whole set of latches is much longer than the typical duration of the latch locks. Nevertheless the couple of screens from the yesterday’s tests (it was V11.7.3):
05/01/19 Activity: Summary
16:12:37 05/01/19 16:12 to 05/01/19 16:12 (6 sec)
Event Total Per Sec
Commits 348622 58103.7
0 Servers, 101 Users (101 Local, 0 Remote, 100 Batch), 0 Apws
05/01/19 Activity: Latch Counts
16:12:37 05/01/19 16:12 to 05/01/19 16:12 (6 sec)
----- Locks ----- Naps
Owner Total /Sec /Sec
MTX 28 1394490 232415 2595
BIB 28 1050568 175094 0
TXT 28 1394486 232414 0
AIB -- 2 0 0
TXQ -- 697247 116207 0
BHT -- 105 17 0
BUF -- 30 5 0
BUF -- 60 10 0
BUF -- 60 10 0
BUF -- 60 10 0
05/01/19 Activity: Summary
16:13:32 05/01/19 16:13 to 05/01/19 16:13 (6 sec)
Event Total Per Sec
Commits 349029 58171.5
0 Servers, 101 Users (101 Local, 0 Remote, 100 Batch), 0 Apws
05/01/19 Activity: Latch Counts
16:13:32 05/01/19 16:13 to 05/01/19 16:13 (6 sec)
----- Locks ----- Naps
Owner Total /Sec /Sec
MTX 23 1396104 232684 2548
BIB 90 1051806 175301 0
TXT -- 1396107 232684 0
AIB -- 2 0 0
TXQ 14 698054 116342 0
BHT -- 119 19 0
BUF -- 34 5 0
BUF -- 68 11 0
BUF -- 68 11 0
BUF -- 68 11 0I run the test with –nosavepoint: no disk IO, particularly during MTX locks.
The highest MTX locks per sec were at 20 sessions: 600,000-700,000 locks/sec vs. 200,000 locks/sec in the tests with BI writes.
Naps start growing with 23 sessions and reached the max with 50 sessions: 1,600 naps/sec vs. 2,600 naps per sec at 100 users in previous test.
Conclusion: disk IO (BI writes) does increase the duration of MTX latch locks.
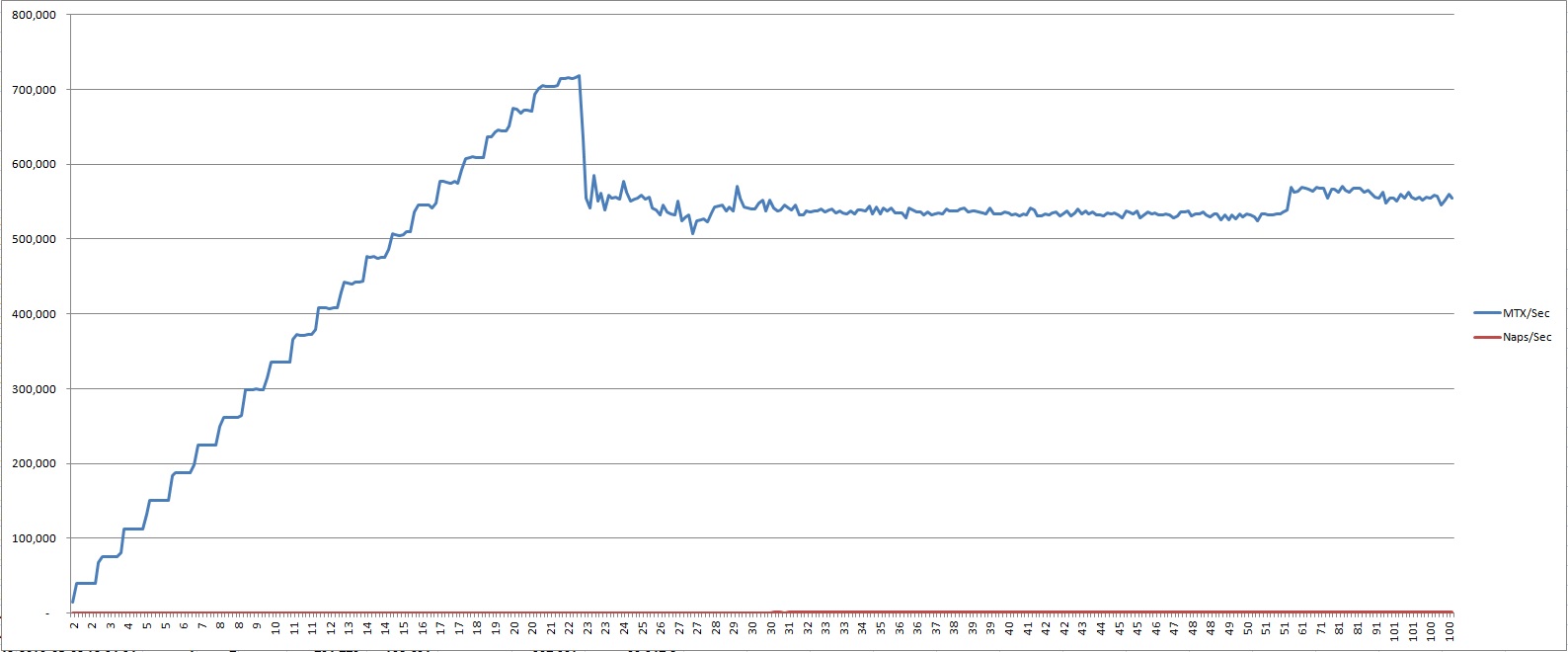
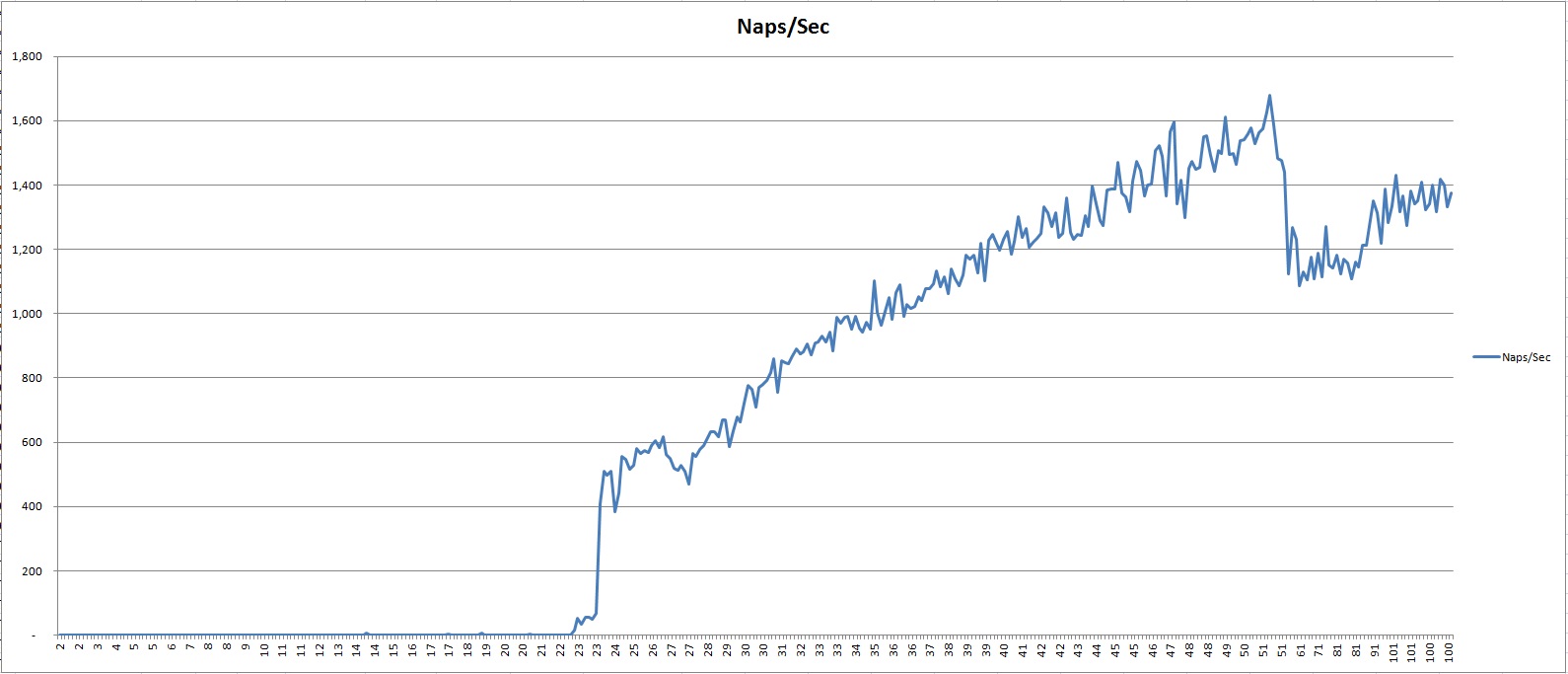
Only two latches were locked: MTX and TXT.
Zero naps of TXT latch. But I don't see that both latches were locked by the same session.
> On May 2, 2019, at 5:27 AM, George Potemkin wrote:
>
> Note that the code of writeprobe above creates only 3 recovery notes per transaction (RL_TBGN, RL_TMSAVE, RL_TEND)
there is a slight flaw here. note that the create and the delete were optimized away by the 4GL runtime. what’s left should also be optimized away since no database change was made. but in the real world, this isnt going to happen much.
> Can somebody explain when these latches are locked individually and when they are locked under the cover of MTX latch
the TXT latch is (mostly) used while holding the MTX latch. same with TXQ.
LKT is often not used while also holding MTX
some of the other things that can happen while holding MTX are:
- writes to before-image log
- formatting new before-image cluster
- expanding before-image extent
- writes to after-image journal
- expanding after-image extent
- after-image extent switch
- writes to database extents
- use of BIB latch
- use of AIB latch
> there is a slight flaw here.
Flaw is a “good thing” (C) when it’s used to steal the secrets... at least for a “thief”. ;-)
> LKT is often not used while also holding MTX
I guess it’s not intended to use LKT to start or to commit a transaction. Maybe it’s a bug in version 12.0? Like the updates of activity counters in promon that scans the whole buffer pool in V11.7/12.0 consuming a lot of CPUs when -B is large.
BTW, what can cause the breaks on the graph of MTX naps in the test with -nosavepoint? Both breaks happened when the number of sessions was a few time smaller (23 and 50) than the number of CPUs (96). The breaks are rather sharp.
> On May 2, 2019, at 9:54 AM, George Potemkin wrote:
>
> I guess it’s not intended to use LKT to start or to commit a transaction.
no, but there are circumstances wherein a lock table entry is added or removed while holding mtx.
starting a transaction ivolves getting the next transaction id and allocating a transaction table entry.
committing is a bit more complicated (e.g. 2pc) and among other things, requires releasing or downgrading locks which require fiddling with the lock table.
> On May 2, 2019, at 10:09 AM, George Potemkin wrote:
>
> what can cause the breaks on the graph of MTX naps in the test with -nosavepoint?
how many bi buffers did you have? i will guess, with /absolutely no evidence/ (aka a "WAG") to support it, that you reached some sort of equilibrium point between spooling of before-image notes and activities of before-image writer.
further experiments could shed light on this WAG
> how many bi buffers did you have?
Default: -bibufs 20
But the test with -nosavepoint does not use BI file.
Hello,
It was a very interesting discussion. Thank you!
About the MTX latch I also see large values per second for this database. That's not good?
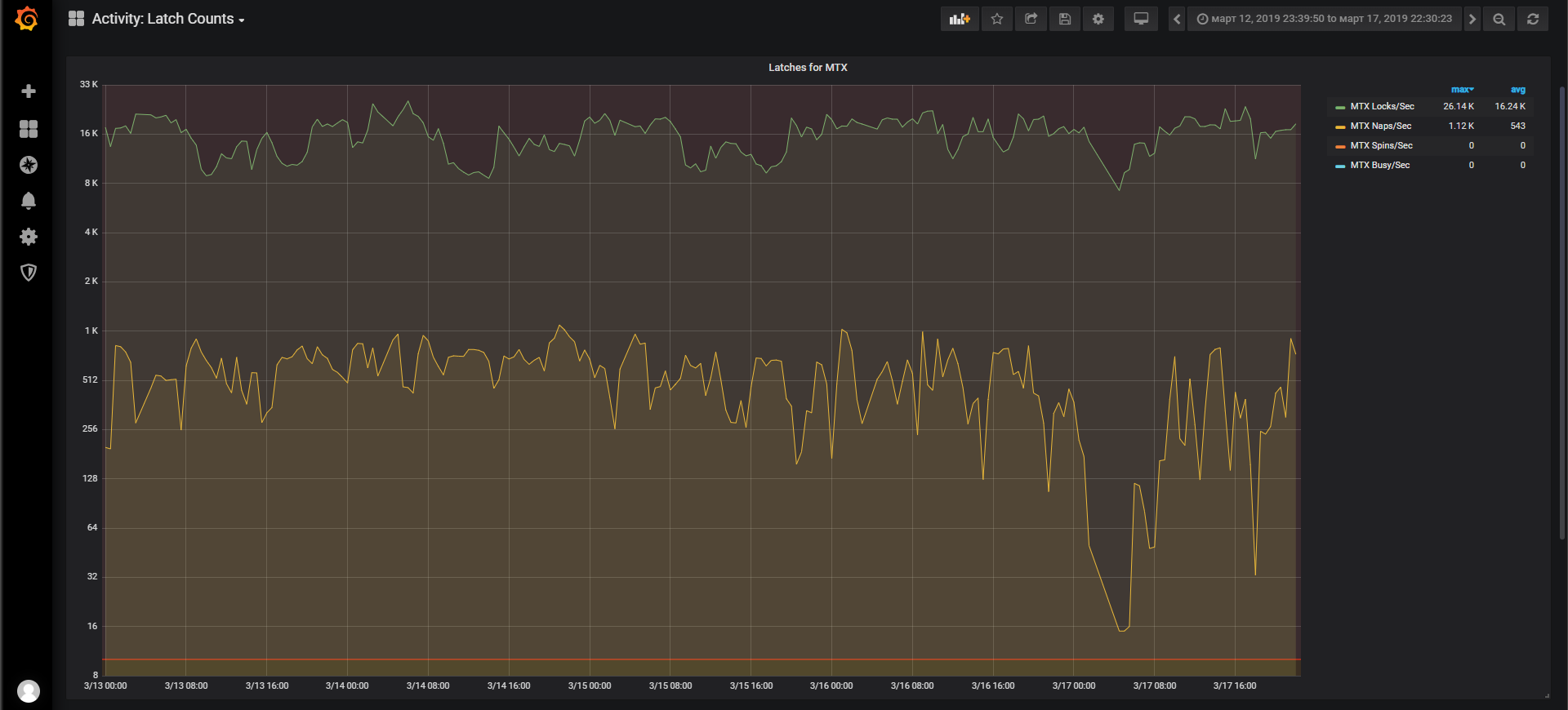
About 128 CPU. There are 15 databases running on this server. These fifteen databases are part of one large application. And it's only in one branch. A separate server is used for each branch. My colleagues told me that earlier, a long time ago, it was a single database. But because of the very high MTX, they had to eventually split this single database into several in order to spread the load and resource utilization, including for MTX.
Also, each client connects to all fifteen databases at once when logging in to the application.
For this database is set -Mn=900/-Mi=1/-Ma=30. However, I don't know why, for other databases on this server the value of -Ma is 1. That is, in this database one server process serves up to 30 clients, while in other databases one server process serves only one client. Is it possible that because of -Ma=30 we have high MTX and BHT latches in this database?
Also, if I understand correctly, one physical server is running at the same time -Mn=900 * 15 DB server processes for remote clients. Wouldn't it be better if we had a lot of CPU for better performance?