
As per Rob's suggestion, splitting this out of the thread https://community.progress.com/community_groups/openedge_rdbms/f/18/t/28190 as it is a little tangential!
Paul, BogoMIPS and IO Response for the last 8 hours side by side (bearing in mind that this server is hardly used over night)
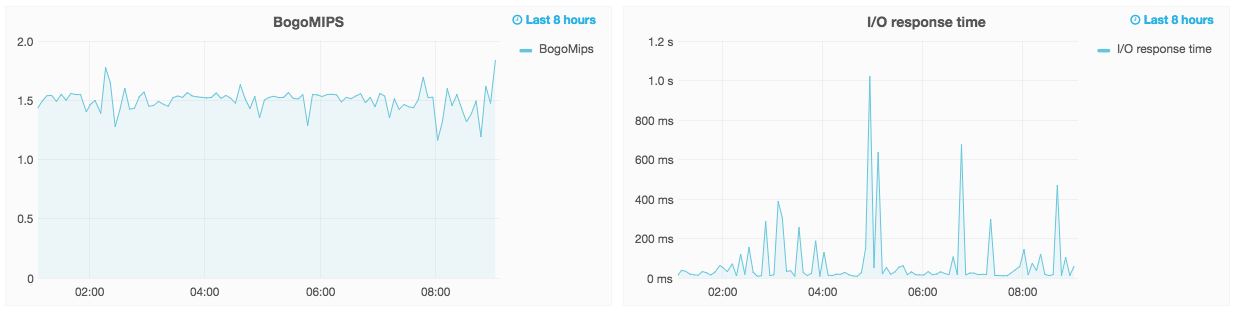
The server is virtualised in a datacentre, but as far as I know it has been isolated onto its own host to try and solve the performance issues. It is the server for 2 of our clients who are owned by the same parent company.
A number of the performance problems are parameter/configuration related. I can resolve that, but I'm trying to build a picture we can go back to the customer with because they are convinced it's not related to hardware. The fact we have our application installed on a lot of other hardware without the issues they are seeing doesn't really cut it for them!
1.5 BogoMIPS is equivalent to a circa 2005 CPU. It's hard to find anything that slow these days. The current state of the market for middle of the road new servers is roughly 3 to 4. If you are performance focused and willing to spend money 5 is easily attainable.
The ioResponse is horrible. Are those floppy drives?
I would ask the hosting people for some detailed specifics about what the configuration is. If they have in fact dedicated an isolated server to this VM then they have made some curious choices about the capabilities of that server.
You probably won't get anywhere. It is very likely a "cookie cutter" VM implemented by the lowest bidder.
James, for comparison here is IO response from one of my internal VMware VMs on a slow, low-end SAN:
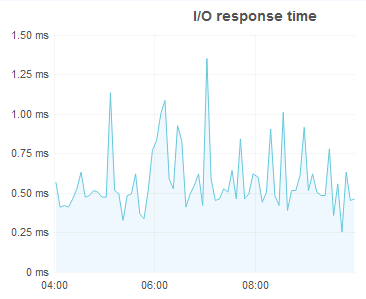
[mention:4b133177ec1e4b6f9a6a7832e6f29913:e9ed411860ed4f2ba0265705b8793d05] that's just mean. :-)
Thanks Rob! :)
For future reference it would be nice to know who is doing the hosting and the name of the plan the customer is on. For extra credit, also the CPU model and speed.
Hey group, I found this topic intriguing and ran some tests of my own.
Frugal test result is 15.3 seconds for a 96 MB BI file.
My network guy was not impressed with my findings. What question do we need to consider to understand the results. What will speed up the OE11.5 function? It seems that throughput is not the bottle neck. My network guy offers a 5 GB file copy as an example. Tom, hold off on the "apply linux patch" solution. In this case the server is Windows 2008 R2, 64 bit, with 64 bit OE11.5.
Bigrow comes in at about 7 MB/s
File copy from a PC to the server in a shared folder at about 100 MB/s. The server is a VM. From the PC to the VM is a 1 GB network with the drive on ISCSI SAN.
File copy from the server c drive to d drive at about 450 MB/s. C drive on the server is VMDK store and D drive is direct connect to SAN RAID 10.
1) The Furgal test is a test of UNBUFFERED WRITES. Copying a file is a test of *buffered* writes. The disk subsystem is free to lie to you about whether or not the disk has actually written the data. And disk subsystems lie like politicians.
This is the kind of IO that Progress does when writing to the BI file. It is very important when determining what to expect for *transaction* throughput.
2) The ProTop ioResponse metric is a test of random disk reads. This is what happens when data is not in your -B cache. It tells you how well your disk subsystem can be expected to respond when you are *reading* data.
15.3 seconds is pretty bad. It is not unusual for a SAN. But, as I have been saying for years, SANs are not there to make anything go fast. There is no such thing as a "high performance SAN". There are only SANs that are not quite as bad as other SANs.
The Linux patch would, of course, make lots of sense but that's another discussion ;)
Follow up about #2. Is there a related 'unbuffered' vs *buffered* read impact when looking at file copy results vs DB reads? I am looking for the point to make with my network guy on the read side. I expect he will be looking at the file copy example again to site that the subsystem can perform well.
On the same server, in ProTop I see IO Response values around 1.1 What is the unit of measure of the value?
There's no real point to doing unbuffered reads.
ProTop's ioResponse metric is in milliseconds.
A SAN is bad for reads because the data is at the wrong end of a cable. The only way to get around the physics of that cable (and the inevitable latency thereof) is to eliminate the cable and use *internal* storage. The best option today is some sort of PCIe SSD option -- that's where those numbers Paul shared with io response of 0.1ms come from. (That system has a FusionIO PCIe card in it). The second best option is a plain old SSD sitting in a drive bay.
A long time ago rotating rust was very slow, physically large, of limited capacity and they were expensive. You could only put so much capacity inside a server. In those days the added latency from being at the wrong end of a cable was outweighed by being able to spread the IO across many devices as well as by the fact that the latency was a *much* smaller proportion of the overall IO operation. So SANs were the best that we could do for a while.
In today's world a *cheap* SSD can do 200,000 IO ops per second. If those IO ops are at the other end of a cable the overwhelming majority of the time that it takes to get a response is the the latency going across that cable (and through the various disk adapter layers and other shenanigans inside the SAN...) That cheap SSD is also probably more than big enough to hold your database.
It does not help to have SSD inside your SAN. That is the wrong place for it and it does not suddenly make your random IO 100x faster. Basically all that does is transfer a large sum of money from your company to the SAN vendor. For database workloads fancy tiered storage is sometimes slightly faster than less fancy SANs. *Slightly* faster. Sometimes.
Database read operations are *random*. So it doesn't help to be able to stream sequential data over that cable at gigabits per second -- which is what your network guy probably pays attention to. Copying a file is a streaming sort of operation -- you pay for the latency *once*, with the first block. So it doesn't matter. But with random access you pay for the latency with each and every operation.
If you have a database that is constrained by IO (IOW you have already tuned -B and you have reasonably well written queries) the simplest and most cost effective thing that you can do to improve performance is to put the db on an *internal* SSD. It's the closest thing to magic that your users are likely to ever see.
THANK YOU.
And of course we all know that using Filesystem storage for a database is as bad as using a database for filesystem storage. Don't we?
"filesystem" per se isn't really the issue -- raw devices are a thing of the past so everything is on a "filesystem" of some sort. Mike probably meant to say "file storage". Auto-correct must have jumped in and ambushed him ;)
The issue is that general purpose file storage can be reasonably implemented on devices that are sometimes called "file servers" and which a certain vendor of very poorly performing devices refers to as "filers". These are "file oriented" use cases. The primary goal of optimization on these devices is usually to minimize cost. The first victim of cost optimization is performance. The next victim is reliability. Thus such devices are anathema to databases.
Databases need filesystems that are on devices that are optimized for random reads and synchronous, unbuffered writes. These are sometimes referred to as "block oriented" devices.
Thanks Mike!
Someone needs to explain to customers and their IT people what SANuside is: ( The act of intentionaly causing one's own data bottleneck. Risk factors include believing the hosting company, the SAN vendor, IT personel having verified "it's not a hardware problem" and/or following someone else's "standard" or "best" practices list).
adding a few more things to the excellent points made by others:
I often hear the claim that copying a large file is fast, and implying therefore that
0) the high performance san is fine
1) anything that is not fast is implemented wrongly
2) the OpenEdge database is the cause of whatever the current performance problem happens to be
copying a large file over a network or from one device to another is one of the easiest of all storage system use cases. all the i/o is sequential, block size does not matter, latency does not matter, the input can be buffered, the output can be buffered, and a return code of ok can be given without anything actually being written to the output device.
a well implemented file copy operation will do read-ahead of the input and write-behind of the output and overlap disk and network operations for both the input and the output. since all the i/o is buffered and non-blocking, once the output file is closed, the operation can be considered complete even though all the data may still be in memory. none of that is recoverable in the event of a crash. all that is required is lack of filesystem corruption if a crash occurs - data corruption and lost files are allowed.
this simple use case is very different from what is required for the type of i/o operations needed to do transaction logging, which has to enable the database to recover complete and incomplete transactions during crashes.
and one more thing:
right or wrong, long experience by many people over many years with many different storage systems and OpenEdge releases has taught us that if the bi-grow test takes longer than 10 seconds or so, that correlates strongly with bad database and application performance caused by improper storage implementation and/or configuration.
it is not the be-all end-all diagnostic but it is a very reliable indicator.
[mention:f68479208c304f10a501457d2d6380ca:e9ed411860ed4f2ba0265705b8793d05] I now happen to know this is AMD Processors (6380 I think). I believe they are 2.5Ghz.
Out of interest we've been working on this particular customer with [mention:dc2ff39fa15940708b78017f1194db6a:e9ed411860ed4f2ba0265705b8793d05] 's help.
So far we've had them isolate the VM again as it had been moved to a shared host again. We've also, at Tom's suggestion, had them reduce the number of vCPUs from 8 to 2. This has had a slight impact for good.
During discussions we found that the data centre had used an old clone of a server to build this VM. We've asked them to rebuild a new VM for us from scratch (and patching it to vmware 6 instead of the 5.5 that is in production) and we will be benchmarking this.
If that still fails to help matters they have an Intel based box we can try running against.
I'll keep this thread updated as it's quite an interesting problem.
Great. Thanks for the update. The bigrow test results have proven to be very insightful.
Have you compared bigrow with bigrow -r?
Adding the non-raw (-r) parameter improves the bigrow time by not needing to sync the bi files when the grow/format is complete. This then gives you an idea of approximately the performance difference that could be achieved with/without the additional amount of time it takes to sync bi files on completion