
Hi,
Windows
OpenEdge 10.2B08 Replication plus
I have done an index compact on the source database. The target database is behind. The number of transaction processed on the target was slow (1 transaction in 4 seconds).
I have restarted the replication and now it says 'Startup synchronization' and the number of transactions is still very slow, 1 transaction in 4 seconds.
Current Source Database Transaction: 4487378093
Last Transaction Applied to Target: 4487371502 <= The value of 'Last Transaction Applied to Target" add 1 in 4 seconds.
We checked the line between the two servers, but we could not see any congestion. Both servers are doing nothing.
So why is it very slow?
Kind regards,
Edwin.
Did the slow tx processing start after the idxcompact?
Do you see any obvious bottlenecks on the target? Checkpoint length? BI Cluster Size? Look at the ckpt screen in ProTop or ProMon and post the results.
Are pica buffers filling on the source side? Look at pica Used% in ProTop or promon - R&D - 1 - 16.
Our application is not running. I have restarted the database with different port number. So no processes could create transactions. What we see is that rpserver.exe is reading the AI file with 2 MB per second on the source. The -pica was 50,000. I have changed this to 8192 to see if this influence the number of transactions. But everything stays the same. We are now investigating the target server. It is a VM with netapp SAN. So perhaps the SAN is very busy.
I did not check this before, so I don't know if this is normal or not.
Hmmm NetApp....
In 10.2B08 there are new columns in the ckpt screen: Duration and Sync Time. If Sync Time is high and you are ckpt'ing often then it very likely is an issue with the disk I/O subsytem.
Try the Furgal Test on the target file system and share the time results with us please:
prodb sports sports
proutil sports -C truncate bi -bi 16384
time proutil sports -C bigrow 2
This will create a 6 X 16 MB = 96 MB BI file.
We are now sure that the Netapp is the issue (of course ;-). We are going to investigate this. Thanks for your help.
Out of interest, Paul, or anyone else, what sort of time is 'good' for the Furgal test.
It depends on the sizes you specify. In my version of this, I use 32 MB cluster size and add 4 additional clusters, for a total of 256 MB of writes (32 * (4 + 4)). I consider less than 6 seconds good, and less than 10 is acceptable. I've seen everything from 3 seconds to several minutes. So if you're using the sizes Paul specified, divide accordingly. I'd be interested to see what elapsed times others see in the field.
To be sure we're talking about the same thing:
_proutil DB -C truncate bi -bi 16384
time _proutil DB -C bigrow 2 [-zextendSyncIO in 11+]
This will create a 96 MB BI file.
10 seconds for a decent SAN.
0.5 seconds on an SSD.
Anything more than 10 seconds and I start to break into hives.
Rob: I routinely see 10-ish seconds on "Enterprise" SANs to create a 96 MB BI file.
Paul
Results of the similar tests on the customer's hardware:
12:16:40 Writing 12.5 MB in unbuffered (O_DSYNC) mode by 1 threads (biWriteTest). 12:16:45 real 0m3.62s 12:16:45 3.45 MB/sec 12:18:18 Writing 12.5 MB in unbuffered (O_DSYNC) mode by 32 threads (biWriteTest). 12:18:44 real 0m1.58s 12:18:45 2.57 MB/sec --- 23:00:26 Writing 12.5 MB in unbuffered (O_DSYNC) mode by 1 threads (biWriteTest). 23:00:27 real 0m0.80s 23:00:27 15.62 MB/sec 23:00:29 Writing 12.5 MB in unbuffered (O_DSYNC) mode by 64 threads (biWriteTest). 23:00:30 real 0m0.23s 23:00:30 17.12 MB/sec --- 13:53:38: Writing 100 MB in unbuffered (O_DSYNC) synchronous mode by 1 threads (bigrow). 13:53:52: real 0m14.116s 13:53:52: 7,08 MB/sec 13:53:52: Writing 100 MB in unbuffered (O_DSYNC) synchronous mode by 2 threads (bigrow). 13:54:03: real 0m10.938s 13:54:03: 9,14 MB/sec
Testing on a customer site where we're seeing very high IO response fluctuations in protop, and it's taking 10-13 seconds to do the 96MB file. The whole site has been plagued by various performance issues, so this may well be part of the problem.
Using the BIGROW command to grow 6 x 16 MB cluster makes a 96 MB file. Take the time and do the math to determine the physical write speed. This helps to determine the correct Bi Cluster Size setting. IMO cluster formatting should not take more than 2 seconds, because that would be a noticeable pause for application users.
So when Paul breaks out in hives is when the physical write speed is 9.6 MB per second, so the largest BI Cluster size in this case would be 20 MB (I am a fan of powers of 2, so I would make it 16 MB or 24 MB).
In rare cases where the update activity requires a larger BI Cluster size than the physical write speed can support, this is when you can pre-grow many BI Clusters, typically 2 times the normal high water mark to make sure there is no unplanned growth or pauses. The downside of this is the online backup time to backup the BI file, unless you are on 11.5 or higher.
When I say high fluctuations...
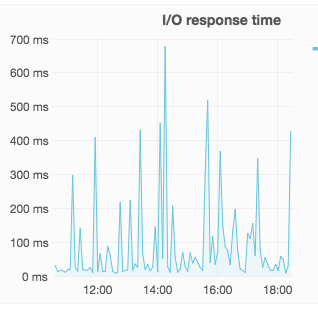
That's bad James.
This is a "not great" IBM SAN and it's still 10X faster than your client. That spike on the left is the backup.
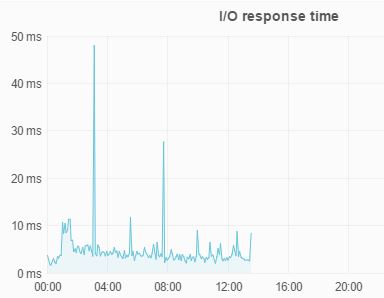
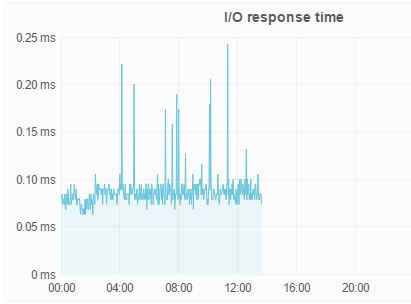
This is local flash at another customer that actually cares about disk I/O:
Can you post bogoMIPS please?
> Testing on a customer site where we're seeing very high IO response fluctuations in protop, and it's taking 10-13 seconds to do the 96MB file. The whole site has been plagued by various performance issues, so this may well be part of the problem.
That depends on the nature of the performance problems and the extent to which they are write-related. But if the I/O subsystem is very slow for unbuffered writes, I wouldn't be terribly surprised if it's also slow for reads. Certainly worth exploring, but maybe in a new thread as it likely isn't related to Edwin's issue. ;)
Hey Mike, since when is 24 a power of 2? :)
Well, he didn't say *integer* powers of 2... ;)