
I'm having fun. :)
Here's another example application that shows how to mix machine learning algorithms with the Corticon APIs to generate rulesheets from data tables.
|
Best regards,
Harold
|
I'd say this would even work with Prescriptive modelling in Corticon :) Nice post Timothy, thank you! And yes, a YouTube-movie would be much appreciated.
I'm using a framework to accomplish the machine learning bits so a video would be rough (almost all of the magic happens on lines 93-100 of Program.cs)...I can link you to the resources I used when researching though. They'll have much more detail.
This explains the decision trees based on learning algorithms: https://crsouza.com/2012/01/04/decision-trees-in-c/
The example application puts all of this together and shows how to use the ID3 algorithm to turn this:
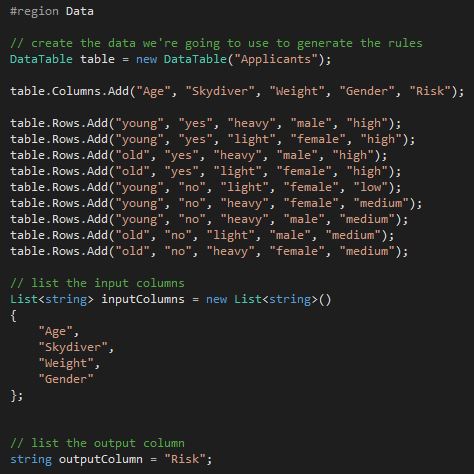
into this:
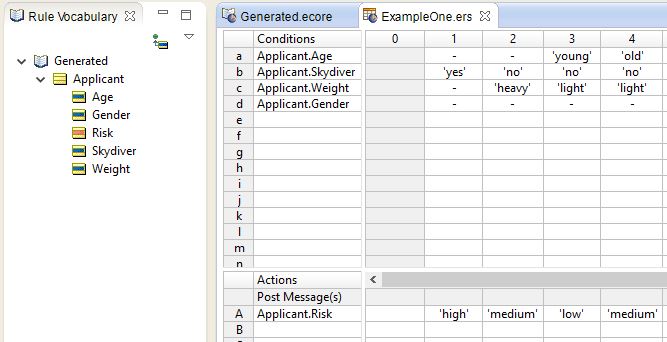
I haven't tested with anything more complex than what's pictured but, since Run() of the ID3Learning class can take an array of outputs, more complex actions can probably be supported.
Going one step further, I see no reason why the data couldn't come straight from a database or why, using something similar to the methods used in the CorticonVocabularyBuilder example, we couldn't auto generate the vocabulary to go along with it. :)
Small update.
The repo has been updated to use Excel spreadsheets and I've switched from ID3 to C4.5 to increase accuracy of the rules against unseen data.
Also, here's a short intro video to the example application. https://youtu.be/KUSznNmuvLA :)
Tim,
After the 5.6 release we're going to explore this further for potential inclusion in the product. The thinking is we would have a "Rulesheet Generation Wizard" which allows you to
- Pick a source for the data (initially a spreadsheet, future a db)
- Pick your input and outcome columns
- Potentially pick a machine learning algorithm
And you're off to the races.
If we pursue this as a product feature it would all be java (there is a java implementation of C4.5).
Does this approach make sense to you?
Do you think there is value in offering different algorithms? Suggestions for which?
We have a "hack day" coming up. Someone may take this up during it.
The approach makes sense; I'm especially fond on the wizard part. It's sounds like an approachable way to present the concepts.
Offering different algorithms would be beneficial. I can see cases where people would want to fit the training data as best as possible (ID3)...and cases where the training data may not be a complete of a picture (C4.5).
There is an update to C4.5 (C5.0) I but I don't have access to a C# version for testing. For the sample applications, accuracy on unseen test cases ranged from 94% to .5%.
If I didn't have any formal rules to begin with, I'd consider that an acceptable starting point!
I'd like to up this topic. Has any progression been made on this, Timothy/ Jim ?
FYI, Marian Cicel will be building upon this work for the coming Innovation day. Still not commitment on productizing it.
Thank you for the update, Jim!